Anonym ist es sicherer


Daten sind ein zentraler Unternehmenswert. Die in den vergangenen Jahren aufgekommenen Big-Data-Technologien ermöglichen die massenhafte Speicherung von Daten, unter diesen natürlich auch in großen Teilen personenbezogene Daten.
Allerdings unterliegt die Speicherung und Verarbeitung genau dieser Daten gesetzlichen Vorgaben. Grundlagen dafür bilden unter anderem das BGB mit seinem auch für Daten geltenden Eigentumsvorbehalt sowie Spezialregelungen in den entsprechenden Umfeldern wie zum Beispiel das SGB X mit den Auflagen für Patientendaten.

Mit dem Inkrafttreten Ende Mai 2018 ersetzt auch noch die europäische Datenschutz-Grundverordnung (EU-DSGVO) mit ihren jeweiligen nationalen Anpassungen das bisherige Bundesdatenschutzgesetz.
Im Ergebnis bedeutet das: Standardmäßig ist es nicht erlaubt, personenbezogene Daten zu speichern. All diese Vorschriften definieren jedoch auch Ausnahmen, wann es dann doch wieder zulässig ist.
Solch eine Ausnahme, wie sie heute typischerweise umgesetzt wird, ist eine zweckgebundene Einwilligung für die Erfüllung einer Geschäftsbeziehung – zum Beispiel für die Ausführung einer Bestellung, Erbringen einer Serviceleistung, Zusenden eines Newsletters.
Mit den Erlaubnissen entsteht jedoch schnell der Eindruck, auch diese Daten könnten wie andere Unternehmensdaten nahezu beliebig verarbeitet werden. Unternehmen müssen jedoch sehr genau darauf achten, wo welche Daten gespeichert und verarbeitet werden – personenbezogene Daten unterstehen eben einem besonderen Schutz.
Personendaten gehören nicht aufs Testsystem
Kritisch ist die Nutzung personenbezogener Daten auf Test- und QS-Systemen oder für Entwicklungssysteme, sowohl im SAP- wie auch im Nicht-SAP-Umfeld. Auch eine Einwilligung erlaubt dort keine Verarbeitung personenbezogener Daten, weil die Einwilligung wie oben beschrieben oft zweckgebunden erhoben wird.
Das schließt Entwicklung und Test nicht automatisch ein. Auch bei Big-Data-Analytics werden allzu gerne Konzepte genannt, die eine Rundum- Sicht auf den Kunden verbessern.
Nur so könne man dem Kunden noch bessere und für ihn geeignete Produkte und Services verkaufen. Dazu müssten natürlich sehr viele detaillierte Daten zur Einzelperson gesammelt, gespeichert und analysiert werden.
Big-Data-Szenarien beziehen sich somit oft auf personenbezogene Daten, was im Kern jedoch nicht zwingend notwendig ist. Auch mit nicht personenbezogenen Daten lassen sich nachweisbar interessante neue Geschäftsmodelle entwickeln.
Einer der wichtigsten IT-Trends für 2018 wird die Vermarktung von Daten durch die Anwenderunternehmen sein. So bestätigte unter anderem das Marktforschungsunternehmen IDC, dass bis 2020 etwa 90 Prozent der großen Unternehmen direkte Umsätze mit dem Verkauf von Rohdaten oder aus daraus abgeleiteten Erkenntnissen oder Empfehlungen generieren werden.
2017 waren es noch 50 Prozent. Daten sind also eine Ressource, die erschlossen, gelagert und veredelt werden können. Die Technik für das Sammeln, Lagern und Veredeln von Daten wurde in den letzten Jahren weiterentwickelt – ob durch kostengünstige Speichersysteme oder neue Datenbankkonzepte.
Eine der wichtigen Aufgaben für IT-Leiter und die Verantwortlichen für die digitale Transformation wird es deshalb sein, die Vermarktung der eigenen Daten aufs Gleis zu setzen, und zwar auf das richtige.
Die Kapitalisierung von Daten ist voll im Trend. Allerdings dürfen das aufgrund der genannten gesetzlichen Bestimmungen nur in seltenen Fällen personenbezogene Daten sein.
Anonymisieren oder löschen?
Keine Probleme gibt es bei der Kapitalisierung von Informationen mit anonymisierten Daten. Die Libelle AG aus Stuttgart, bislang bekannt für ihre Lösungen rund um die Hochverfügbarkeit von SAP- und Non-SAP-Datenbanken und SAP- und Non-SAP-Systemkopien, hat das Know-how aus diesen beiden Themenbereichen weiterentwickelt und mit Libelle DataMasking (LDM) eine Lösung für die erforderliche Anonymisierung und Pseudonymisierung entwickelt.
Konzipiert wurde die Lösung zur Herstellung anonymisierter, logisch konsistenter Daten auf Entwicklungs-, Test- und QS-Systemen über alle Plattformen hinweg. Die eingesetzten Anonymisierungsverfahren liefern realistische, logisch korrekte Werte, mit denen fast alle Geschäftsfälle beschrieben und sinnvoll Ende-zu-Ende getestet werden können.
Zu den Ansätzen der Behandlung kritischer, insbesondere personenbezogener Daten vor einer Weitergabe oder Weiterverarbeitung gehören die Pseudonymisierung und die Anonymisierung. Eine gute Anonymisierung kann jedoch schwieriger sein, als es auf den ersten Blick scheint.
Eine einfache Möglichkeit ist das Löschen oder Überschreiben kritischer Echtdaten auf den nicht produktiven Systemen. Allerdings verlieren die einzelnen Datensätze dabei ihre logischen Verbindungen und Abhängigkeiten zueinander – und somit ihren Nutz-wert.
Pseudonymisierung
Bei einer Pseudonymisierung werden Echtdaten durch falsche Daten, in der Regel einfache Zahlenwerte, ersetzt. Es reicht jedoch vielfach nicht aus, beispielsweise in der Kundendatenbank Name, Vorname und Geburtsdatum oder Ähnliches durch falsche Werte zu ersetzen.
Oft reicht ein einfacher Abgleich solcher Datenbanken mit öffentlich zugänglichen Telefonbüchern, um auch den Personenbezug wiederherzustellen. Deshalb sollten besondere hochwertige Verfahren zur Anonymisierung verwendet werden.
Libelle DataMasking ist eine Lösung für die automatisierte Behandlung sensibler Daten. Sie erlaubt es, beliebig komplexe Datenbestände mit umfassenden Anonymisierungsmethoden zu behandeln.
Vorkonfigurierte Funktionen können schnell und einfach auf Datenfelder angewendet werden, die als kritisch und sensibel identifiziert wurden. Fachliche und/oder technische Verantwortliche können so auf standardisierte Regeln zurückgreifen und darüber hinaus beliebig komplexe Regeln aufstellen, mit denen sich beispielsweise hochstrukturierte und sprechende Datentypen berechnen lassen.
Saubere Daten für Entwicklung und Test
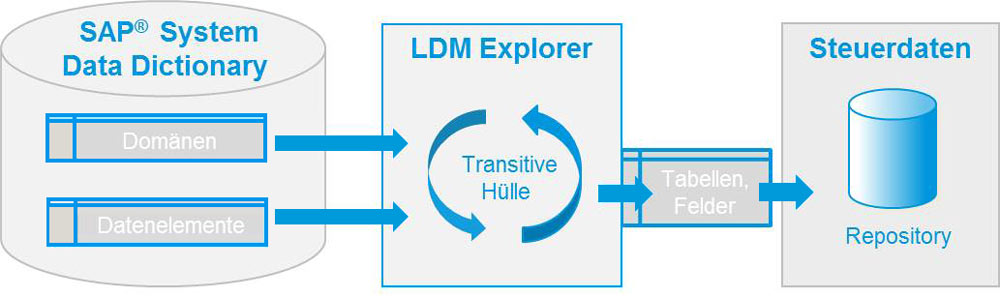
Nicht immer ist für die Anwendungsbetreuer und -programmierer ersichtlich, welche Daten tatsächlich zu den sensiblen Daten gehören. Eine zentrale Komponente der Anonymisierungslösung von Libelle ist der LDM Explorer zur einmaligen oder nach Strukturveränderungen auch wiederkehrenden Analyse der Datenbanken und Dateisysteme und deren jeweiligen Datenmodelle nach zu anonymisierenden Inhalten.
Die verantwortlichen Personen prüfen, verifizieren und ergänzen gegebenenfalls die Ergebnisse des LDM Explorer, um diese dann per LDM Assoziator mit typischen Anonymisierungsverfahren zu verknüpfen.
Dies bildet die Basis für eine automatische, logisch durchgängige und konsistente Anonymisierung zusammenhängender Datensätze über Systemgrenzen hinweg. Für die Standardsituationen bietet LDM derzeit 75 standardisierte Anonymisierungsprofile.
Sind die Daten einmal identifiziert und mit den entsprechenden Anonymisierungsverfahren verknüpft, greifen die operativen Anonymisierungsschritte des LDM. Diese behandeln dann neben den unternehmensspezifischen Spezialfällen bereits out of the box Namensfelder, Adressinformationen, Bankdaten und Daten wie Geburtsdatum, Bestelldatum. Auch Indizes werden, sofern betroffen, neu aufgebaut.
Weitere Szenarien
Entwicklern und Anwendern steht so eine „saubere“ Datenbasis zur Verfügung, mit der sie sich keine Sorgen um den Datenschutz machen müssen. Dabei sind viele weitere Einsatzszenarien für Libelle DataMasking denkbar – darunter die eingangs genannten Beispiele für die Weitergabe anonymisierter Daten im Rahmen einer Supply Chain, im Kontext eines offenen Datenpools oder bei einer kommerziellen Vermarktung.




