Missing Datenlink


Datenintegration: Echtzeitzugriff für Echtzeitentscheidungen
Es sind schnelle Entscheidungen gefragt, für die ein Echtzeitzugriff auf die Daten erforderlich ist. Dabei stehen vor allem drei Hürden im Weg, die wir uns in diesem Artikel genauer ansehen werden. Wie Unternehmen diese überwinden können, zeigt im Anschluss das Beispiel von Pitney Bowes, einem globalen Anbieter von Versand- und Postbearbeitungslösungen, E-Commerce-Logistik und Finanzdienstleistungen.
99 Prozent der Unternehmen kämpfen mit Problemen bei der Datenintegration. Für 65 Prozent ist allein schon der Zugang zu ERP-Daten schwierig. Das sind Ergebnisse einer kürzlich von Dimensional Research und Fivetran durchgeführten weltweiten Umfrage unter ERP-Experten. Die Auswirkungen des fehlenden Datenzugriffs sind massiv: 82 Prozent der befragten ERP-Experten sagen, ihr Unternehmen arbeitet mit veralteten Daten. 85 Prozent sehen dies als Ursache für falsche Entscheidungen. Verzögerungen bei der Datenanalyse und damit auch bei wichtigen Entscheidungsfindungen nennen rund 70 Prozent als Problem. Nicht einmal ein Viertel der Befragten hat derzeit Echtzeit-Zugriff auf ERP-Daten. Warum ist dieser Anteil hier so gering? Drei Hürden erschweren Unternehmen die Integration von SAP-ERP-Daten.


Die hohe Belastung der Unternehmen durch isolierte SAP-ERP-Daten.
Begrenzter Zugang
Mehrere Faktoren erschweren den Echtzeit-Zugriff. Zu den wichtigsten Faktoren zählen: die immense Menge an Daten, die in SAP-Systemen gespeichert sind; die Geschwindigkeit, mit der stetig neue Daten generiert werden; und die Vielfalt der unterschiedlichen Datenformate und -quellen.
Doch der Zugriff ist nicht das einzige Problem. Hinzu kommt, dass die Daten nicht konstant zur Verfügung stehen, sondern im Gegenteil sehr volatil sind. Außerdem ist es mit dem Zugriff allein nicht getan. Erst die Verknüpfung der SAP-Daten mit Daten aus weiteren Unternehmenssystemen und externen Quellen – idealerweise in Echtzeit – erlaubt Unternehmen, Erkenntnisse daraus zu ziehen. Auch daran scheitern viele. Denn das Tempo, in dem neue Daten generiert werden, steigt weiter. Und die weiter zunehmende Nutzung von Smartphones und Social Media sowie interaktiven Geschäftsprozessen sorgt für eine oft lähmende Komplexität. Das gilt vor allem, wenn es darum geht, ERP-Daten mit anderen betrieblichen Funktionen wie CRM, Sales oder unstrukturierten Quellen zu integrieren. Doch nur damit erhalten Unternehmen eine einheitliche Sicht auf ihre Daten – und ein riesiges Potenzial, diese zu nutzen.
Um beispielsweise aus OLTP-Daten (Online Transactional Processing) mittels OLAP (Online Analytical Processing) nutzbare Erkenntnisse zu gewinnen, müssen die Daten extrahiert, umgewandelt und zur Analyse in ein Data Warehouse geladen werden. Bislang war es üblich, OLTP- und OLAP-Systeme nicht zu durchgehend synchronisieren. Stattdessen wurden die Daten täglich oder monatlich mithilfe von inhouse entwickelten Datenpipelines und manuellen Prozessen in die Analysesysteme geladen. Damit haben Nutzer zwar Zugriff auf Daten, diese sind aber veraltet.
Keine nahtlose Integration
Die Thematik stellt Unternehmen vor die Aufgabe, die ideale Balance zwischen dem Zugang zu SAP-Daten in der nötigen Geschwindigkeit und Größenordnung einerseits und den Kosten für die Installation, Lizenzierung oder Entwicklung entsprechender Tools andererseits zu finden. Bisher war das kaum ein Problem, weil ERP-Daten nur gezielt für ganz bestimmte Zwecke exportiert wurden. Doch inzwischen ist es zunehmend unternehmenskritisch, enorme Mengen an Unternehmensdaten schnell und skalierbar nutzbar zu machen.
Um die Kosten dennoch möglichst gering zu halten, bauen viele Unternehmen eigene Datenpipelines. Ihre Daten-Spezialisten sehen sich jedoch mit der fast unlösbaren Aufgabe konfrontiert, mit den explodierenden Datenmengen Schritt zu halten. Ständig kommen neue Produktlinien und neue Datensätze hinzu, sodass Unternehmen ihre Datenpipelines kontinuierlich anpassen oder gar neu aufbauen müssen. Das erschwert nicht nur eine nahtlose Datenintegration, sondern bindet auch viel wertvolle Zeit von Data Scientists und Data Engineers.
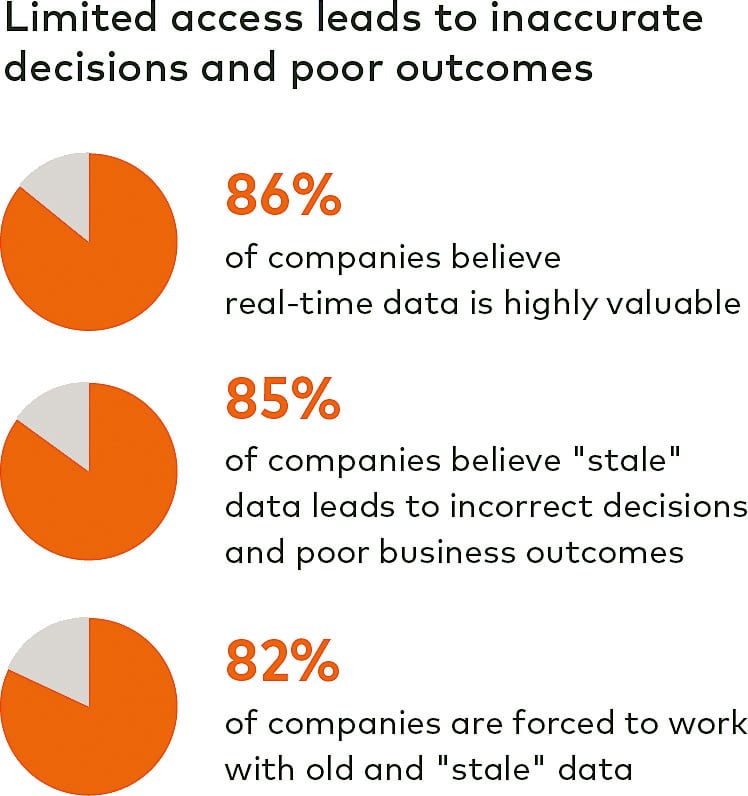
Begrenzter Zugang führt zu ungenauen Entscheidungen und schlechten Resultaten.
Keine optimale Nutzung
Die Tatsache, dass viele Unternehmen nicht den vollen Mehrwert aus ihren SAP-ERP-Daten nutzen können, hat mehrere Gründe: Komplexität, Daten verteilt auf unterschiedliche Silos und Quellen, zum Beispiel Cloud und On-premises; der Mangel an qualifizierten Fachleuten bremst die Entwicklung von DIY-Datenpipelines; und Sicherheitsbedenken beziehungsweise fehlende robuste Sicherheits- und Datenschutzkonzepte halten viele Unternehmen davon ab, ihre SAP-ERP-Daten zu nutzen.
Wie können Unternehmen diese Hürden überspringen? Nur mit skalierbaren und automatisierten Datenpipelines können Unternehmen ihre SAP-Daten so nutzen, dass sie den größtmöglichen Nutzen daraus ziehen. Denn nur so lassen sich die weiterwachsenden Datenmengen in den Griff bekommen, SAP-ERP-Daten mit unstrukturierten Datensystemen integrieren und Einsichten in Echtzeit gewinnen. Der kostengünstigste Weg, um dieses Ziel zu erreichen, ist die Replikation großer Datenmengen mithilfe der logbasierten Change-Data-Capture-Technologie (CDC). Bei der Datenreplikation werden Daten, die sich auf einem physischen oder virtuellen Server oder einer Cloud befinden, kontinuierlich auf einen zweiten Server oder eine zweite Cloud-Instanz kopiert.
Geht es um ERP-Daten, muss eine solche Datenreplikationslösung die hier vorliegenden immensen Datenmengen verarbeiten können. Für einen Zugriff in (nahezu) Echtzeit muss sie zudem in der Lage sein, Änderungen auf dem Primärserver – dem SAP-System – zu erfassen und in Echtzeit an ein Zielsystem – eine Cloud-Plattform oder ein Data Warehouse – zu übermitteln.
Es gibt mehrere CDC-Methoden, um die Änderungen zwischen Datenbanken zu replizieren. Für große Datenmengen empfiehlt sich die logbasierte CDC-Technologie. Sie gilt als überlegene Replikationsmethode, da sie große Datenmengen schnell und mit minimalen Auswirkungen auf die Transaktionsquellen verarbeiten kann.
Datenstrukturen eines SAP-Systems müssen viele Satelliten berücksichtigen und integrieren.
Best Practice
Pitney Bowes bietet Versand- und Postbearbeitungslösungen, E-Commerce-Logistik und Finanzdienstleistungen, die von rund 750.000 Kunden weltweit genutzt werden. Sein Enterprise-Information-Management-Team (EIM) extrahierte für das Sales Reporting jede Nacht Daten sowohl aus SAP als auch aus Oracle. Das Volumen der Datenintegration von SAP nach Snowflake war erheblich gewachsen, der Batch-ETL-Prozess benötigte bis zu 31 Stunden. Auch die steigende Zahl an Unternehmen, die SAP-Daten für Dashboards und Reportings anfragten, war mit den alten ETL-Prozessen nicht mehr zu bewältigen.
Weil das bestehende System nicht skalierbar war, um diesen wachsenden Anforderungen gerecht zu werden, entschied sich Pitney Bowes für ein CDC-Tool von Fivetran. Neben der hohen Flexibilität, Geschwindigkeit und Skalierbarkeit spielte auch die nahtlose Integration mit der Snowflake-Datenbank eine Rolle bei der Auswahl. Außerdem hatte Pitney Bowes Schwierigkeit, eine Lösung zu finden, die mit SAP kompatibel ist. Fivetran konnte mit einem Feature Set punkten, das Pitney Bowes die einfache Replikation aus SAP erlaubt.
Heute synchronisiert, validiert und repliziert Pitney Bowes viermal täglich Daten aus Oracle und SAP in das cloudbasierte Data Warehouse. Damit haben die Nutzer Zugang zu aktuellen SAP- und Oracle-Leasing-Daten als „Single Source of Truth“ in einer Unternehmens-Datenbank ohne irgendwelche Auswirkungen auf die Quellanwendungen. Der größte Teil des Replikationsmanagements wird über das Interface abgewickelt. Das heißt: Die für die Batch-Verarbeitung erforderliche manuelle Überwachung entfällt.
Pitney Bowes konnte sowohl für seine Oracle- als auch für seine SAP-Systeme deutlich schnellere Verarbeitungszeiten feststellen. ETL-Jobs, die früher Tage dauerten, werden jetzt in weniger als einer Stunde erledigt. Somit kann das EIM-Team die steigenden Anforderungen nach Oracle-Leasing- und SAP-Daten erfüllen. Zudem wurde der „technical footprint“ des Datenerfassungsprozesses minimiert, das heißt, redundante Software-Lizenzen konnten gekündigt, Hardware und Datenspeicher reduziert werden.

