Data Mesh und SAP Datasphere: Neue Wertschöpfung aus Daten für alle Fachbereiche


Die Entwicklung der Business-Datenhaltung und Auswertung reicht von den ersten Data Warehouses der 1980er-Jahre über die Konzepte Data Lakes, Hubs und Lakehouses. Zunächst konnten Unternehmen aus den Zahlen die Vergangenheit ablesen und Schlüsse ziehen, dank sauberer Daten, Reports und schneller Auswertungen. Seit den 2010er-Jahren ist die Leistungsfähigkeit der Rechner und der Anwendungen auf einem Level, wo auch Vorhersagen (Predictive Analytics) und Handlungsempfehlungen (Prescriptive Analytics) möglich sind.
Viele Chancen, hohe Hindernisse
Daten und Datenanalysen gelten als Treibstoff für die digitale Transformation und den Wandel zum intelligenten Unternehmen. Aber die Hindernisse sind zahlreich:

- Daten-Silos machen es schwer, relevante Daten zu finden und darauf zuzugreifen.
- Zentrale physikalische Architekturen limitieren die Datennutzung, schaffen Flaschenhälse für die benötigte Rechenleistung.
- Die traditionelle Datenintegration ist arbeitsintensiv, komplex und verzögert den Zugriff auf neue, wichtige Datenquellen.
- Data-Teams sind häufig mit Grundlagenarbeit überlastet und müssen sich parallel um die Anfragen aus dem Tagesgeschäft kümmern.
Diese Hürden lassen sich technisch überwinden, dazu später mehr. Eine Voraussetzung ist aber zunächst eine Datenkultur im Unternehmen, die die effektive und ethische Nutzung von Daten zur Entscheidungsfindung und Innovation fördern möchte. Ohne positive Datenkultur werden Organisationen keine datengesteuerten Unternehmen werden können.
Häufig beginnt eine positive Datenkultur mit einem Umdenken bei den organisatorischen Prinzipien. Beispielsweise bieten aktuell nur wenige Unternehmen allen Mitarbeitenden die Möglichkeit, eigenständig Datenanalysen zu erstellen (per Self-Service). Gerade in der Eigeninitiative und Kreativität der Fachbereiche liegt aber ein Schlüssel zur neuen Wertschöpfung aus Daten. Generell gilt: Eine Organisation sollte sich die Haltung, die Praktiken und Werte bewusst machen, die den effektiven und verantwortungsvollen Umgang mit Daten fördern – dazu gehören Transparenz, Vertrauen, Datenkompetenz, Ethik und Kollaboration.
Data Mesh: eigenständige und dezentrale Datenanalysen
Viele Unternehmen haben in der Vergangenheit in einen zentralen Data Lake und ein Datenteam investiert und erwartet, ihr Geschäft auf der Grundlage von Daten voranzutreiben. Nach einigen anfänglichen Erfolgen stellen sie jedoch fest, dass das zentrale Datenteam oft zum Engpass wird: Das Team kann nicht alle analytischen Fragen des Managements, der Produktverantwortlichen und Fachbereiche schnell genug beantworten. Gerade zeitnahe datengestützte Entscheidungen sind aber entscheidend für die Wettbewerbsfähigkeit. Typische Fragestellungen sind:
- Kann ein höherer Preis bei kürzerer Lieferzeit durchgesetzt werden? Akzeptieren die Kunden längere, aber zuverlässigere Lieferzeiten?
- Sollten wir in bestimmten Märkten unser Portfolio eingrenzen oder ausweiten?
Das Datenteam möchte all diese Fragen schnell beantworten. In der Praxis hat es jedoch Schwierigkeiten, weil es zu viel Zeit damit verbringt, Datenpipelines anzupassen und gegebenenfalls operative Datenbankänderungen durchzuführen. In der wenigen verbleibenden Zeit muss das Datenteam die erforderlichen Domaindaten ermitteln und verstehen.
Obwohl die Fachbereiche ihre Domains und den relevanten Informationsbedarf kennen, müssen sie sich an das überlastete zentrale Datenteam wenden, um datengestützte Erkenntnisse zu erhalten.
Ein Ausweg besteht darin, die Verantwortung für die Daten vom zentralen Datenteam auf die Bereichsteams zu übertragen. Dies ist der Kerngedanke des Data-Mesh-Konzepts: domainorientierte Dezentralisierung für analytische Daten. Eine Data-Mesh-Architektur ermöglicht es Fachbereichen und Domainteams, domainübergreifende Datenanalysen selbst durchzuführen und Daten miteinander zu verbinden, ähnlich wie APIs in einer Microservice-Architektur.
Die vier Grundprinzipien des Data Mesh
Das Domain-Ownership-Prinzip verpflichtet die Domainteams, die Verantwortung für ihre Daten zu übernehmen. Diesem Prinzip zufolge sollten analytische Daten um Domains herum aufgebaut sein, ähnlich wie die Teamgrenzen, die sich an den begrenzten Kontext des Systems anpassen. Im Rahmen der bereichsorientierten verteilten Architektur wird die Verantwortung für analytische und operative Daten von einem zentralen Datenteam auf die Bereichsteams übertragen.
Der Grundsatz Data-as-a-Product projiziert das Produktdenken auf analytische Daten. Dieses Prinzip bedeutet, dass es für die Daten Verbraucher außerhalb der Domain gibt. Das Domainteam ist dafür verantwortlich, die Bedürfnisse anderer Domains durch die Bereitstellung hochwertiger Daten zu befriedigen. Im Grunde sollten Domaindaten wie jede andere öffentliche API behandelt werden.
Die Idee hinter der Self-Service Data Platform besteht darin, den Plattformgedanken auf Dateninfrastruktur zu übertragen. Ein spezielles Datenplattform-Team stellt bereichsunabhängige Funktionen, Werkzeuge und Systeme zur Erstellung, Ausführung und Pflege interoperabler Datenprodukte für alle Bereiche bereit. Eine moderne Daten-Plattform ermöglicht den Domainteams, Datenprodukte nahtlos zu nutzen und zu erstellen.
Eine Federated Governance ermöglicht die Interoperabilität aller Datenprodukte durch Standardisierung. Ziel ist die Schaffung eines Datenökosystems unter Einhaltung der organisatorischen Regeln und Branchenvorschriften.
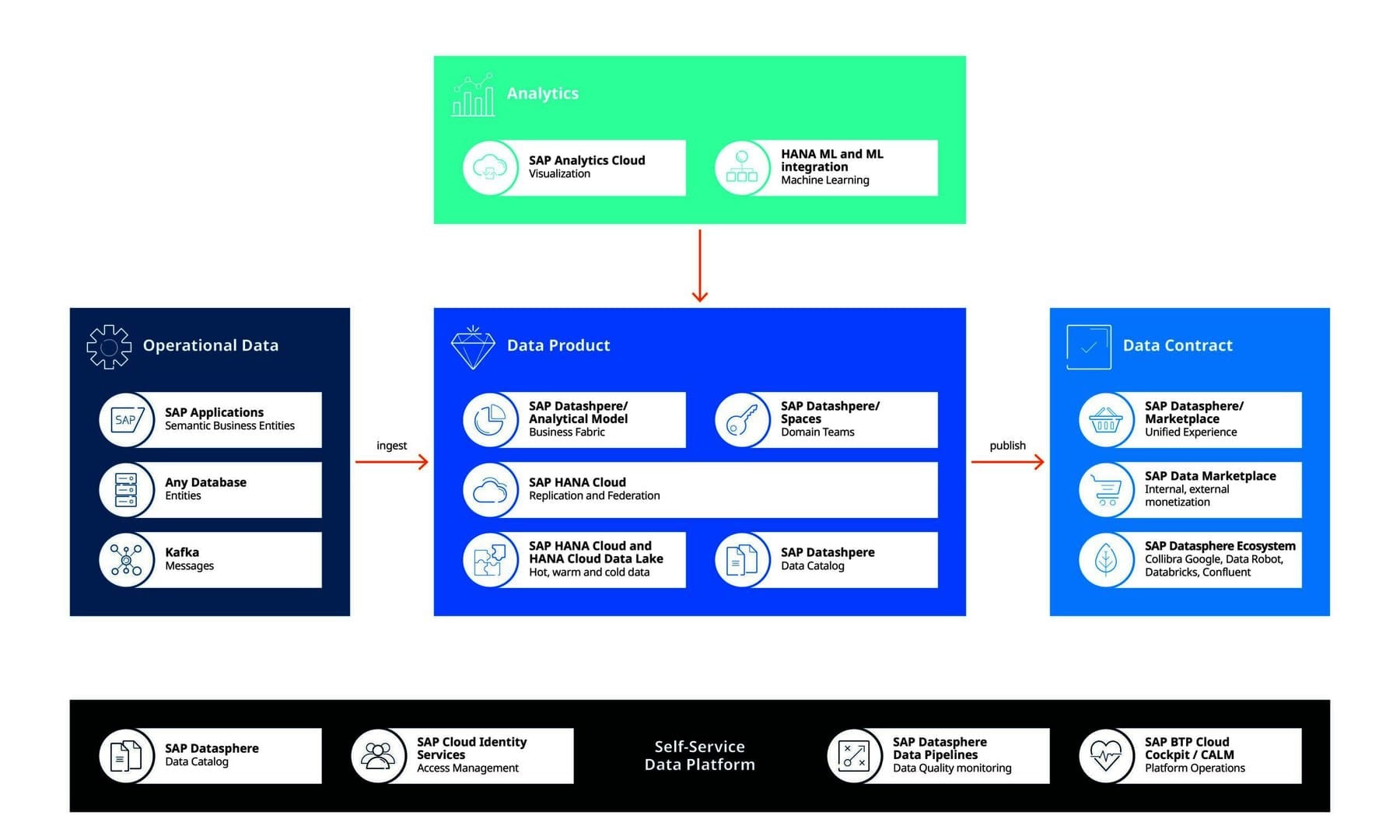
Warum Data Mesh mit SAP Datasphere?
Eine neue Datenwertschöpfung benötigt neben den genannten organisatorischen Kriterien eine technologische Basis – wie beispielsweise das leistungsfähige und intuitiv bedienbare Datenmanagementsystem SAP Datasphere.
Diese ermöglicht einen nahtlosen und skalierbaren Zugriff auf geschäftskritische Daten, indem sie eine harmonisierte Datenschicht für alle SAP- und Nicht-SAP-Datenquellen schafft, egal ob Cloud, On-Prem oder Hybrid. Funktional verbindet die Lösung Datenintegration, Datenkatalogisierung, semantische Modellierung, Data Warehousing, Datenföderation und -virtualisierung.
Basis dafür können Data Lakes sein, Anwendungen, Webservices und weitere Datenquellen. Durch Kombination und Konsolidierung entsteht ein Single Point of Truth. Im Hintergrund kombiniert die Lösung In-Memory-Technologien mit einer Reihe von leistungsfähigen Data Engines. Die Anwender aus den Bereichsteams können ihre Daten mit intuitiven grafischen Werkzeugen modellieren und erweitern. So schaffen sie wertvolle Erkenntnisse für ihr Unternehmen.
SAP Datasphere hält dabei die Balance zwischen dem Datenbedarf der Anwender und den Governance-Anforderungen des Unternehmens. Da die Lösung Cloud-nativ arbeitet, wächst sie mit den Anforderungen und eignet sich auch für Unternehmen mit weniger als 1000 Mitarbeitern.
Zum Partnereintrag:


