

The decisive advantage of SAP RPT-1 over the popular LLMs from OpenAI or Anthropic lies in the fundamental way in which data is processed. Conventional language models are brilliant rhetoricians, but often fail miserably at simple arithmetic or the precise interpretation of series of numbers. When an LLM sees the number „1000“, it is often broken down into individual tokens, such as „1“, „0“, „0“ and „0“, and treated as a sequence of characters rather than a mathematical value, which can lead to the infamous hallucinations during calculations.
RPT-1 and relational values
RPT-1, on the other hand, recognizes „1000“ as a single relational value, which massively increases precision when analyzing business data such as that found in SAP's MARA tables or sales databases. Where a text-based model hallucinates or misunderstands the context of a complex table structure, RPT-1 acts like a specialized „GPT for tables“ that natively understands the semantic logic of rows and columns without having to take a detour via language. In the heated debate about artificial intelligence, which is usually dominated by the linguistically adept all-rounders from Silicon Valley such as ChatGPT or Claude, SAP is trying to make up ground with a technical niche solution that goes by the cryptic abbreviation RPT-1. While the world gazes in amazement at large language models (LLMs) that write poetry and generate code, SAP is returning to its true DNA: the mundane but business-critical database tables.
RPT-1, which stands for „Relational Pre-trained Transformer“, is an attempt to transfer the Transformer technology that founded the success of OpenAI and Anthropic from the unstructured world of language to the highly structured world of relational enterprise data. It is SAP's first real „foundation model“ that was developed specifically for tables and not for text, and thus marks a strategically necessary counter-design to the language-based models of the US competition. Another major advantage lies in its efficiency and the elimination of time-consuming training phases for specific tasks. In the traditional world of machine learning (ML), companies had to train and maintain a separate, dedicated model for each problem - be it predicting customer churn, fraud detection or demand planning - which tied up enormous resources in the data science teams.
In-Context Learning
RPT-1 breaks with this paradigm through so-called in-context learning. The model does not have to memorize the customer-specific data or undergo lengthy training; instead, it reads the data during inference time, makes the prediction and „forgets“ the data immediately, similar to an exam where the textbook is allowed to lie open on the table. This not only drastically lowers the hurdle for deployment, but also significantly reduces resource consumption compared to the token-hungry LLMs of hyperscalers, as no huge amounts of text need to be processed.
The possible applications of this model are aimed right at the heart of ERP processes. SAP is positioning RPT-1 for scenarios in which speed and precision are more important than eloquence. A small version of the model, the so-called Speedster, is optimized for millisecond latency times and is designed to block fraudulent transactions in real time, for example. Larger versions of the model address complex tasks such as predicting supply chain bottlenecks or payment risks. Tasks that conventional ML pipelines often take hours to calculate, while RPT-1 delivers results almost instantly. The model also offers new approaches to IT operations management for the technical monitoring of the SAP landscape itself - for example, to predict whether batch jobs or interfaces will fail at the end of the month.
RPT-1 and LLMs
Based on the available sources (https://community.sap.com/), the technical difference between SAP RPT-1 (Relational Pre-trained Transformer) and the LLM approaches of OpenAI (such as GPT) can be fundamentally determined by the type of data processing and the architecture, see box. While OpenAI models are language models for unstructured text data, RPT-1 is a specialized foundation model for structured, tabular business data.
However, despite all the technical finesse, a critical classification is essential. In the SAP community, RPT-1 is sometimes viewed skeptically as part of an „AI chaos theory“. Critics note that RPT-1 is in fact a „narrow-gauge“ LLM that may simply be selling old wine in new bottles. There is a suspicion that mechanisms such as the „Predictive Analysis Library“ (PAL) of the Hana database are still being used under the hood.
work, supplemented by modern marketing terms so as not to lose touch with the AI hype.
Abap tables „only“
Furthermore, as innovative as the approach to tables may be, RPT-1 is limited in its range of applications: It works exclusively on tables, not text or images, and is therefore not a replacement, but at most a supplement to the powerful models of OpenAI. While SAP is trying to regain sovereignty over „business semantics“ with RPT-1, it remains to be seen whether this specialized approach will be enough to stand up to the sheer superiority and speed of innovation of the generative AI giants, which are increasingly learning to handle structured data better. RPT-1 is therefore SAP's bet that, in the ERP environment, the bare figures will ultimately count more than fine words. (pmf)
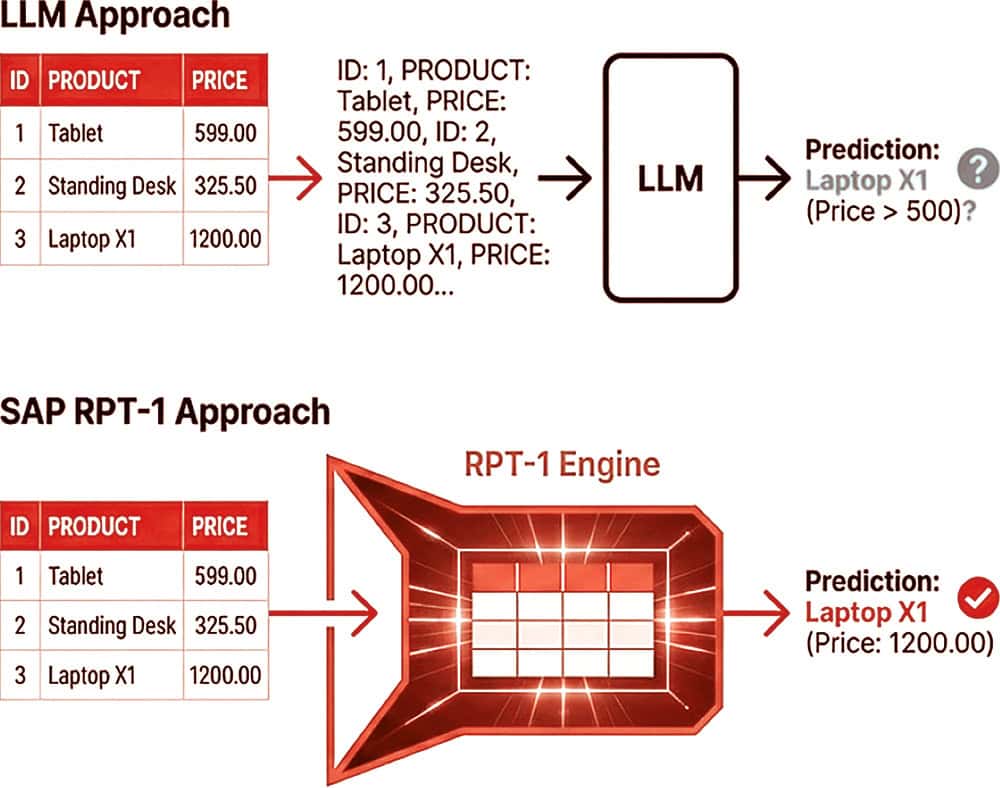
SAP RPT-1 versus ChatGPT
Data modality: table vs. text. With OpenAI (LLM), the models are trained to understand and generate natural language. They work with unstructured text. SAP RPT-1 was developed specifically for tabular data. It acts as a „GPT for tables“. It understands the structure of rows and columns (as in SAP tables MARA or sales data) natively instead of interpreting them as text.
Tokenization and numerical understanding (the „1000“ problem): A technical difference lies in the treatment of numerical values. When OpenAI (LLM) sees the number „1000“, it is often tokenized and broken down into separate characters. The model then tries to perform math based on these text characters, which often leads to hallucinations or calculation errors. RPT-1 recognizes „1000“ as a single relational value. It understands the mathematical meaning and context of the number within the table structure, allowing for more accurate predictions on business data.
Learning methods: In-context learning vs. fine-tuning. In order to solve specific business tasks, LLMs from OpenAI often have to be fine-tuned with new data or require complex RAG (Retrieval Augmented Generation) architectures to obtain context. SAP RPT-1 uses in-context learning. The model does not have to be used for every task.
(e.g. churn prediction or fraud detection) can be retrained. It reads the data at runtime (inference time), makes the prediction and then „forgets“ the data again.
Resources and efficiency: OpenAI (LLM) is resource-hungry, consumes many tokens and requires massive computing power (GPUs) to process context. SAP RPT-1 is optimized for the tabular structure, so it consumes significantly fewer resources (tokens) and performs fewer computational operations (FLOPs). It is more efficient for tasks such as filling missing values in a database or predicting time series.

