Künstliche Intelligenz: Der Schritt von der Idee zur Produktion


Es ist kein Geheimnis, dass jedes Unternehmen weltweit daran arbeitet, das Potenzial von KI und insbesondere von generativer KI auszuschöpfen. Unternehmen wissen, dass KI ihre Effizienz steigern, Kosten senken, die Kunden- und Mitarbeiterzufriedenheit verbessern, Wettbewerbsvorteile schaffen und Geschäftsprozesse automatisieren kann. All dies ist möglich, da die Technologie für Unternehmen jeder Größe immer leichter verfügbar und zugänglich wird. Dank zahlreicher Bereitstellungsoptionen und verschiedener Hardware- und Softwarekombinationen ist der Zugang zu KI- und ML-Technologien einfacher geworden.
Unternehmen benötigen auch kein vollständiges KI-/ML-Deployment mehr, um bestimmte Funktionen wie cloudbasierte KI-Dienste oder KI-gestützte Business-Tools nutzen zu können. Infolgedessen zeichnen sich steigende Investitionen in KI-Technologien ab. Der KI-Markt ist allerdings derzeit sehr fragmentiert. In diesem Umfeld fällt es Unternehmen oft schwer, den richtigen Weg einzuschlagen. Vor allem stehen sie dabei vor der Herausforderung, KI-Modelle effizient und sicher in die Produktion zu bringen. Selbst Unternehmen, die erste KI-Projekte erfolgreich absolviert haben, zögern oder scheitern bei der flächendeckenden Transformation. Dafür gibt es zahlreiche Gründe.

Viele Unternehmen befürchten einen Vendor-Lock-in und sehen die Gefahren und Risiken der KI-Technologie. Andere wiederum sehen in der anforderungsspezifischen Anpassung von KI-Modellen eine schwer zu lösende Aufgabe. Angesichts dieser Herausforderungen bleiben viele KI-Projekte in der Pilot- oder Proof-of-Concept-Phase stecken.

Der Ansatz von Red Hat im KI- und ML-Engineering ist zu 100 Prozent Open-Source-basiert.
Das richtige KI-Modell
Nur ein strategisches Vorgehen, das bereits vor der KI-Einführung elementare Fragen aufwirft und beantwortet, kann den Erfolg sichern. Dazu gehört vor allem die Auswahl der richtigen KI-Modelle und der adäquaten Plattform beziehungsweise Infrastrukturbasis.
Bei der Entscheidung für ein bestimmtes KI-Modell ist ein klarer Trend erkennbar. Immer mehr Unternehmen setzen nicht auf LLMs, sondern auf kleinere Modelle, die für spezielle Use Cases konzipiert sind. Das Problem bei der Verwendung größerer Modelle – mit Milliarden von Parametern – besteht darin, dass sie zwar ein umfangreiches generisches Wissen besitzen, aber nicht sonderlich hilfreich sind, wenn ein Unternehmen einen Chatbot für seine Kundendienstmitarbeiter erstellen oder Kunden bei der Lösung eines konkreten Problems mit einem Produkt oder einer Dienstleistung unterstützen möchte. Im Vergleich zu LLMs bieten kleinere Modelle zahlreiche Vorteile. Sie sind mit geringerem Aufwand zu implementieren und ermöglichen eine kontinuierliche Integration neuer – gerade auch unternehmens- und domänenspezifischer – Daten. Das heißt, mit ihnen sind auch Trainingsläufe deutlich schneller durchführbar.
Die Modelle tragen auch zu einer erheblichen Kosteneinsparung bei, schließlich erfordern große LLMs erhebliche Investitionen. Nicht zuletzt können Unternehmen durch den Einsatz kleinerer Modelle auch die Abhängigkeit von großen LLM-Anbietern verringern, deren Lösungen vielfach eine Blackbox im Hinblick auf Algorithmen, Trainingsdaten oder Modelle darstellen. Generell ist in der Branche derzeit ohnehin eine Tendenz zur Bereitstellung kleinerer und optimierter KI-Modelle vorhanden. Ein Beispiel hierfür liefert der vLLM(Virtual Large Language Model)-Ansatz. Damit können Berechnungen mit einem Inferenzserver schneller durchgeführt werden, beispielsweise durch eine effizientere Nutzung des GPU-Speichers.
Projekt InstructLab
Aber auch generische LLMs, die einen unterschiedlichen Grad an Offenheit in Bezug auf Pretraining-Daten und Nutzungsbeschränkungen aufweisen, können inzwischen für einen bestimmten Geschäftszweck erweitert werden. Hierzu haben Red Hat und IBM das Community-Projekt InstructLab ins Leben gerufen, das eine kosteneffiziente Lösung zur Verbesserung von LLMs bereitstellt. Die Lösung benötigt weitaus weniger Daten und Rechenressourcen für das Retraining eines Modells. InstructLab senkt die Einstiegshürde in die KI-Modellentwicklung erheblich – auch für Nutzer, die keine Data Scientists sind.
In InstructLab können Domain-Experten aus verschiedenen Bereichen ihre Kenntnisse und ihr Wissen einbringen und so ein offen zugängliches Open-Source-KI-Modell weiterentwickeln. Es ist dabei auch möglich, durch die Anwendung der RAG (Retrieval-Augmented Generation)-Technik ein mit InstructLab abgestimmtes Modell zusätzlich zu optimieren. RAG bietet generell die Möglichkeit, die in einem LLM vorhandenen Daten durch externe Wissensquellen mit aktuellen Echtzeitdaten, kontextuellen, proprietären oder domänenspezifischen Informationen zu ergänzen, etwa durch Daten-Repositories oder bestehende Dokumentationen. So kann auch wesentlich einfacher sichergestellt werden, dass die Modelle richtige, sichere Antworten liefern, ohne zu halluzinieren.
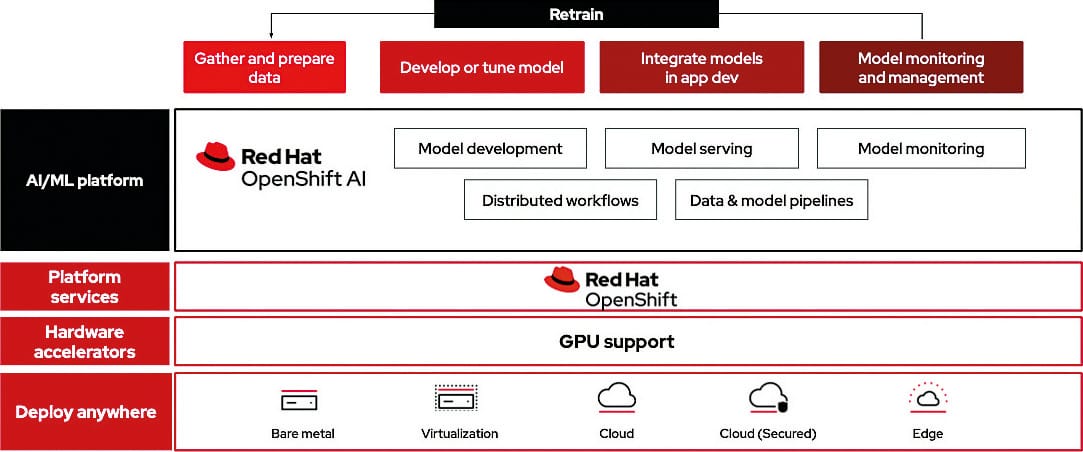
Mit Red Hat OpenShift AI, einer flexiblen, skalierbaren KI/ML-Plattform, können Unternehmen KI-gestützte Anwendungen in Hybrid-Cloud-Umgebungen entwickeln und bereitstellen.
Open-Source-KI
Es steht außer Frage, dass sich Unternehmen im Hinblick auf ihre Wettbewerbsfähigkeit und Zukunftssicherheit verstärkt mit neuen Themen wie KI und ML auseinandersetzen müssen. Ein vorbehaltloser und unkritischer Einsatz ist allerdings nicht vertretbar. Die Sicherheit, Stabilität und digitale Souveränität müssen immer gewährleistet bleiben.
Bei der Souveränität geht es dabei vor allem um die Technologie, den Betrieb und die Daten. Unternehmen sollten auf eine Anbieterunabhängigkeit achten, sowohl hinsichtlich der Wahlmöglichkeit zwischen proprietären und Open-Source-Komponenten als auch im Hinblick auf flexible Bereitstellungsoptionen. Datensouveränität bedeutet, dass Unternehmen wissen, an welchem Ort und mit welcher Methode ihre eigenen Daten gespeichert und verarbeitet werden.
Im Kontext dieser Souveränitätsanforderungen gewinnen transparente Open-Source-Prinzipien, -Technologien und -Lösungen an Bedeutung. Gerade wenn KI in unternehmenskritischen Bereichen eingesetzt wird, muss immer ein hohes Maß an Nachvollziehbarkeit und Erklärbarkeit gewährleistet sein. Unternehmen wollen schließlich keine Blackbox, sondern eine KI, die vertrauenswürdig und erklärbar ist sowie rechtliche und ethische Grundsätze beachtet. Gerade bei der Umsetzung zeigt sich wieder der Wert bewährter Open-Source-Verfahren, die wie zuvor im Bereich der Softwareentwicklung für hohe Transparenz stehen.
Allerdings besteht auch im KI-Bereich, wie in der Softwareentwicklung generell, die Gefahr des Open-Source-Washings, wie ein Vergleich der Kernelemente von Open-Source-Software und Open-Source-LLMs zeigt. Open-Source-Software zeichnet sich aus durch eine vollständige Transparenz, nachvollziehbare Algorithmen, eine einsehbare Fehlerbehandlung und die Möglichkeit, die Weiterentwicklung unter Mitwirkung der Community voranzutreiben. Im Gegensatz dazu kennzeichnet viele der sogenannten Open-Source-LLMs zwar in der Regel eine freie Verfügbarkeit, jedoch bieten sie kaum Einblick in – mit der Softwareentwicklung vergleichbare – Aspekte wie Trainingsdaten, Gewichtungen, modellinterne Leitplanken oder eine belastbare Roadmap.
Aus Unternehmenssicht sind aber Nachvollziehbarkeit und Datengrundlage von fundamentaler Bedeutung, allein schon aus Haftungs- oder Compliance-Gründen. Auch aufgrund der hohen regulatorischen Anforderungen, die sich etwa aus der DSGVO oder dem AI Act der EU ergeben, ist eine vertrauenswürdige KI vielfach unverzichtbar. Ein Open-Source-Ansatz ist dafür die richtige Basis, denn er bietet Transparenz, Innovation und Sicherheit. Allerdings muss es echtes Open Source sein und zentrale Open-Source-Kriterien erfüllen – auch hinsichtlich der Trainingsdaten oder KI-Modelle – und nicht nur Open-Source-Washing.
Die richtige Plattform
Für welchen Weg – Nutzung eines LLMs oder mehrerer kleinerer Modelle – sich ein Unternehmen auch entscheidet: Die genutzte Plattform ist dabei immer ein wichtiger Bestandteil der KI-Umgebung. Viele Unternehmen setzen nach wie vor auf eigene Infrastrukturen und On-premises-Server. Dieser Ansatz schränkt aber die Flexibilität ein, um innovative Technologien wie KI einzuführen. Der Cloud-Markt hat sich allerdings inzwischen weiterentwickelt und bietet das Beste aus beiden Welten: die Hybrid Cloud. Sie ermöglicht es Unternehmen, weiterhin On-premises-Speicher für sensible Daten zu verwenden und gleichzeitig die Skalierbarkeitsvorteile der Public Cloud zu nutzen.
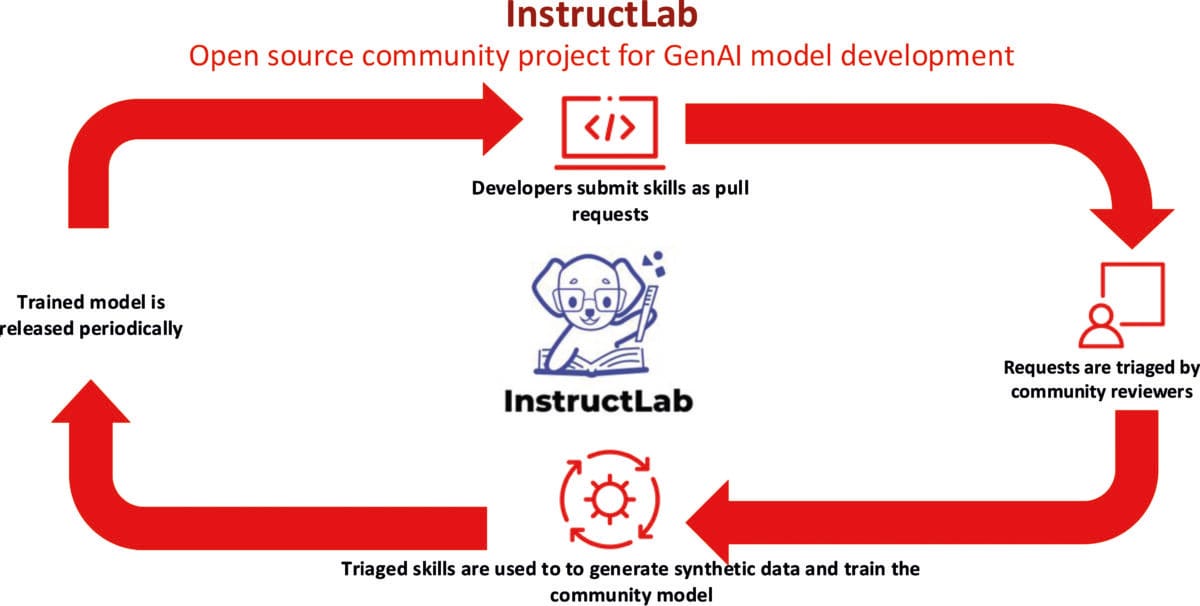
InstructLab ist ein Open-Source-Projekt zur Verbesserung von LLMs. Das von IBM und Red Hat ins Leben gerufene Community-Projekt ermöglicht ein vereinfachtes Experimentieren mit generativen KI-Modellen und eine optimierte Modellanpassung.
Hybrid Cloud für KI
Eine Hybrid-Cloud-Plattform ist damit auch eine ideale Infrastrukturbasis für die sichere KI-Umsetzung, und zwar von der KI-Modellentwicklung über das KI-Modelltraining bis hin zur KI-Modelleinbindung in Anwendungen und zum Betrieb moderner MCP (Model Context Protocol) und A2A (Agent to Agent) Services. Die Hybrid Cloud bietet die dringend benötigte Flexibilität bei der Wahl der besten Umgebung für die jeweiligen KI-Workloads. Für Unternehmen bestehen dabei zwei Nutzungsmöglichkeiten. Sie können ein KI-Modell in einer Public Cloud auf GPU-Farmen mit klarer Mandantentrennung auch unter Verwendung öffentlich verfügbarer Daten und synthetischer Testdaten entwickeln sowie trainieren und es anschließend in die On-premises-Anwendung einbetten. Schließlich ist auch zu berücksichtigen, dass der Aufbau einer kostenintensiven eigenen GPU-Infrastruktur für Unternehmen in der Regel nicht möglich ist. Umgekehrt können sie aber auch die Modelle mit vertraulichen Daten im eigenen Rechenzentrum trainieren und danach in einer Public Cloud betreiben.
Wichtiger Bestandteil einer für die KI-Nutzung konzipierten Plattform sind MLOps(Machine Learning Operations)-Funktionalitäten. MLOps ähnelt dem etablierten DevOps-Konzept, wobei der Schwerpunkt allerdings auf der Bereitstellung, Wartung und dem Retraining von maschinellen Lernmodellen liegt. MLOps trägt vor allem zu einer effektiven und optimierten Zusammenarbeit von Data-Science-, Softwareentwicklungs-Teams und Betriebsbereichen bei. So wird die Brücke geschlagen von der Entwicklung der ML-Modelle bis zum Einsatz in einer Produktivumgebung. MLOps-Praktiken, die auf Vereinfachung, Automatisierung und Skalierung abzielen, tragen somit auch zu einer erheblichen Beschleunigung des Produktions-Roll-outs bei.
Zur Reduzierung der betrieblichen Komplexität sollte eine Plattform auch fortschrittliche Tools für die Automatisierung von Deployments und eine Self-Service-Zugriffsmöglichkeit auf Modelle und Ressourcen bieten. So können Unternehmen ihre Umgebungen für das Training und die Bereitstellung von Modellen je nach Bedarf selbst verwalten und skalieren. Wichtig ist zudem, dass getestete und unterstützte KI/ML-Tools vorhanden sind.
Nicht zuletzt stellt ein Plattformansatz auch sicher, dass Industriepartner, Kunden und die breite Open-Source-Community effektiv kooperieren können, um Open-Source-KI-Innovationen weiter voranzutreiben. Dabei besteht ein immenses Potenzial, diese offene Zusammenarbeit im Bereich der KI auszuweiten, gerade auch bei der transparenten Arbeit an Modellen und ihrem Training.
KI-Produktiveinsatz
Die Welt der KI kann damit weiter geöffnet und demokratisiert werden. Für KI-Nutzer ergibt sich durch die Offenheit der Plattform für ein Hardware- und Software-Partnernetzwerk ein zentraler Vorteil: Sie erhalten die Flexibilität, die sie für die Umsetzung ihrer speziellen Use Cases benötigen. Solche flexiblen und hybriden Plattformen für den KI-Produktiveinsatz sind inzwischen verfügbar, wie das Beispiel Red Hat OpenShift AI zeigt. Damit kann ein Unternehmen einen Vendor-Lock-in ausschließen, mit neuen KI-Innovationen Schritt halten und alle möglichen Anwendungsfälle umsetzen. Sie unterstützt das Modelltraining und Feintuning sowie die Bereitstellung und Überwachung sämtlicher Modelle und KI-Anwendungen, und zwar in der Cloud, an der Edge und on-premises. Die Flexibilität und Kompatibilität werden durch einen modularen Aufbau und eine Plug-and-Play-Funktionalität mit Open-Source-Komponenten und anderen KI-Lösungen sichergestellt. Unternehmen können mit einem solchen Lösungsfundament die KI-Einführung sukzessive und einfach vorantreiben und somit auch die Kosten im Griff behalten.
Viele Unternehmen befinden sich bei der KI-Einführung noch in einer Evaluierungs- beziehungsweise Proof-of-Concept-Phase. Auch wenn sich derzeit viel um große Sprachmodelle und generative KI dreht, darf eines nicht vergessen werden: Die Überführung von KI im großen Maßstab in die Produktivumgebung ist zwar ein eher neues Thema, betrifft aber keineswegs nur LLMs, sondern beispielsweise auch prädiktive oder analytische KI. Auch hier gibt es Herausforderungen, die letztlich nur mit einem Plattformansatz sinnvoll bewältigt werden können.
Weiter zum Partnereintrag:




