Der KI-Motor stottert


KI gilt als Gamechanger für Unternehmen. Aber trotz ehrgeiziger KI-Roadmaps und massiver Investitionen stoßen viele Organisationen auf Hindernisse bei der Realisierung ihrer KI-Initiativen. Das ist das zentrale Ergebnis einer aktuellen globalen Umfrage von Redpoint im Auftrag von Fivetran. So berichtet fast die Hälfte der befragten Unternehmen (42 Prozent), dass mehr als 50 Prozent ihrer KI-Initiativen verzögert, leistungsschwach oder komplett gescheitert ist – vor allem aufgrund mangelnder Data Readiness. Selbst manche Unternehmen mit klar definierten Zentralisierungsstrategien kommen über die Pilotphase nicht hinaus, da Integrationsprobleme, Ressourcenengpässe und operative Ineffizienzen den Fortschritt bremsen. Kurz gesagt: KI kann keine Ergebnisse liefern, wenn Daten nicht vollständig zentralisiert, verwaltet und einsatzbereit sind. Viele Unternehmen verfolgen ambitionierte Pläne, um künstliche Intelligenz zur Verbesserung ihrer Geschäftsergebnisse einzusetzen.
Darum scheitern KI-Ambitionen
In der Praxis jedoch stoßen diese Vorhaben häufig auf erhebliche Umsetzungsprobleme. Zwar geben 57 Prozent der Unternehmen an, dass ihre Datenzentralisierungsstrategie „sehr effektiv“ sei, dennoch räumen 42 Prozent ein, dass über die Hälfte ihrer KI-Projekte scheitert oder unterdurchschnittlich abschneidet. Ein zentrales Hindernis für den Erfolg ist die Integration: Über ein Drittel der Unternehmen nennt sie als Hauptgrund für das Scheitern von KI-Initiativen. Die Folgen dieser Verzögerungen sind gravierend. 68 Prozent der Unternehmen mit weniger als 50 Prozent zentralisierten Daten berichten von entgangenen Umsatzchancen aufgrund von Verzögerungen oder leistungsschwacher KI. Datenteams sind im Wartungsmodus gefangen.

Auch bei Unternehmen, die mehr als die Hälfte ihrer Daten zentralisiert haben, verwenden 67 Prozent über 80 Prozent ihrer Ressourcen für die Wartung der Datenpipelines – und haben damit kaum Kapazitäten für den KI-Fortschritt. Die KI-Bereitschaft beginnt mit zentralisierten Daten – aber die Umsetzung ist entscheidend. Denn 59 Prozent der Unternehmen sehen regulatorische Anforderungen als größte Herausforderung beim Datenmanagement für KI. Das zeigt: Zentralisierung ist wichtig, reicht aber allein nicht aus. Eines der größten Hindernisse für den KI-Erfolg ist die Integrationskomplexität. Nahezu drei Viertel der Unternehmen verwalten oder planen mehr als 500 Datenquellen. Das macht es schwierig, diese unterschiedlichen Daten für KI zu vereinheitlichen und betriebsfähig zu machen.
Die Wartung der Datenpipelines zwischen den Datenquellen und dem Ort, an dem die Daten gebraucht werden, ist ein weiteres großes Hindernis. Anstatt sich auf KI-Innovationen zu konzentrieren, müssen die Datenteams den Großteil ihrer Ressourcen für das Management und die Instandhaltung der Infrastruktur aufwenden: 65 Prozent der Unternehmen geben an, dass sie über 40 Prozent ihrer Ressourcen für die Wartung von Datenpipelines aufwenden.
Selbst die Zentralisierung von Daten ist ohne Automatisierung nicht ausreichend: 67 Prozent der Unternehmen, die mehr als die Hälfte ihrer Daten zentralisiert haben, wenden immer noch über 80 Prozent ihrer Ressourcen für die Wartung auf. Da die Wartungsanforderungen steigen, haben Unternehmen Schwierigkeiten, Kapazitäten für höherwertige KI-Initiativen zu allokieren.
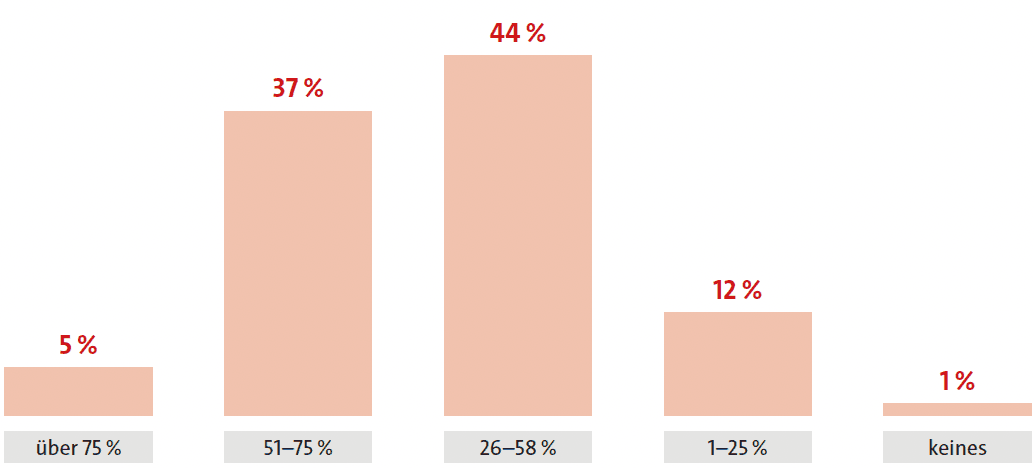
Wie viel Prozent der KI-Projekte in Ihrem Unternehmen haben sich aufgrund von Problemen bei der Data Readiness verzögert, sind hinter den Erwartungen geblieben oder gescheitert?
Mangelnde Data Readiness
Zusätzlich zu Integrations- und Wartungsproblemen untergraben auch schlechte Datenqualität und Schwächen in der Daten-Governance die Effektivität von KI. Dabei gilt regulatorische Compliance (59 Prozent) als größte Herausforderung im Datenmanagement für KI. Aber auch veraltete (52 Prozent) und ungenaue Daten (52 Prozent) verhindern, dass KI-Modelle verlässliche Erkenntnisse liefern. Dazu kommt oft, dass es nur einen eingeschränkten Echtzeitzugang zu Daten (41 Prozent) gibt und KI deswegen keine zeitnahen und handlungsrelevanten Ergebnisse liefern kann.
Obwohl jedes Unternehmen bestrebt ist, das volle Potenzial von KI zu nutzen, sind nicht alle gleichermaßen bereit für die Umsetzung. Dies variiert deutlich nach Branche und Region – und schafft eine wachsende Kluft zwischen KI-Vorreitern und Nachzüglern. Organisationen, denen es nicht gelingt, KI in den operativen Betrieb zu überführen, werden Schwierigkeiten haben, Strategien in echte Wirkung zu übersetzen. Diejenigen hingegen, die über eine starke Datenbasis und Umsetzungsfähigkeiten verfügen, skalieren bereits KI-gesteuerte Transformationen. Um diese Unterschiede darzustellen, wurde für die Fivetran-Studie das „AI Readiness Maturity Model“ entwickelt. Es bewertet Branchen und Regionen anhand der vier entscheidenden Ausführungskriterien Effektivität des Datenmanagements und der Datenintegration, Anteil der KI-bereiten Daten, Erfolgs- beziehungsweise Misserfolgsquote bei KI-Projekten sowie Ressourceneinsatz für die Wartung von Datenpipelines.
Die Zahlen zeigen: KI-Umsetzung ist nicht nur eine branchen-, sondern auch eine regionsspezifische Herausforderung. Organisationen in weniger entwickelten KI-Märkten müssen Automatisierung, moderne Datenintegration und Governance priorisieren, um wettbewerbsfähig zu bleiben.
Kosten mangelhafter KI-Umsetzung
KI ist nicht länger eine experimentelle Technologie – sie ist ein entscheidender Treiber für Effizienz, Umsatz und Kundenbindung. Wenn KI-Initiativen scheitern, gehen die Folgen weit über die IT hinaus. Unzureichende Datenbereitstellung und KI-Ineffizienzen wirken sich auf Geschäftswachstum, Betriebskosten und Kundenzufriedenheit aus.
KI soll die Entscheidungsfindung verbessern, Prozesse optimieren und neue Einnahmequellen erschließen. Ohne verlässliche Informationen und Analysen durch KI fällt es Unternehmen schwer, Markttrends rechtzeitig zu erkennen, Preisstrategien zu optimieren und Maßnahmen zu entwickeln, die Konversion und Kundenbindung fördern: 68 Prozent der Unternehmen mit weniger als 50 Prozent zentralisierten Daten berichten von verpassten Umsatzchancen aufgrund von gescheiterten oder verzögerten KI-Projekten.
KI-Ineffizienzen bremsen nicht nur Innovation – sie erhöhen auch die Kosten. Statt Prozesse zu verschlanken und Abläufe zu automatisieren, geben viele Unternehmen mehr für Infrastruktur, Wartung und die Korrektur fehlerhafter KI-Modelle aus. Viele Unternehmen investieren ihre Ressourcen in die Pflege der Infrastruktur anstatt in Innovation und strategisches Wachstum. So beklagen 38 Prozent der Unternehmen gestiegene Betriebskosten infolge gescheiterter KI-Projekte.
Unzufriedene Kunden
Wenn KI aufgrund von schlechter Datenqualität, Integrationsproblemen oder veralteten Modellen versagt, leidet auch die Kundenzufriedenheit. Unternehmen, die auf KI-gesteuerte Personalisierung und Automatisierung setzen – insbesondere in Branchen wie dem Einzelhandel, dem Finanz- und Gesundheitswesen –, riskieren, dass das Vertrauen untergraben wird, die Konversionsrate sinkt und die langfristige Markentreue leidet.
KI-Initiativen scheitern nicht, weil es an Daten fehlt – sie scheitern, weil Unternehmen diese Daten nicht effizient vorbereiten, integrieren und operationalisieren können. Ohne die richtige Infrastruktur und geeignete Prozesse geraten KI-Projekte ins Stocken, sie verbrauchen Ressourcen, ohne geschäftlichen Mehrwert zu erzielen. Um das volle Potenzial von KI freizusetzen, müssen Unternehmen weg von manueller Datenpflege und hin zu Automatisierung. Nur so können sich Teams auf KI-gestützte Innovation konzentrieren, anstatt die Infrastruktur instand zu halten.
Die Zentralisierung von Daten ist ein entscheidender Startpunkt für einen erfolgreichen KI-Einsatz – aber nur der Anfang. Obwohl 57 Prozent der Unternehmen ihre Zentralisierungsstrategie als „sehr effektiv“ einstufen, sagen gleichzeitig 42 Prozent, dass mehr als die Hälfte ihrer KI-Projekte scheitert oder unterdurchschnittlich abschneidet. Manuell zentralisierte Daten können durch Qualitäts- und Strukturprobleme die Leistung von KI beeinträchtigen. Ohne saubere, KI-bereite Daten erhalten Modelle uneinheitliche Eingaben. Das führt zu ungenauen Vorhersagen und unzuverlässigen Erkenntnissen.
Um das volle Potenzial von KI auszuschöpfen, müssen Unternehmen daher über die bloße Zentralisierung hinausgehen. Eine automatisierte Datenaufbereitung ist ein wichtiger Schritt, um sicherzustellen, dass KI-Modelle mit sauberen und strukturierten Daten versorgt werden. Ergänzend dazu tragen Werkzeuge zur Validierung, Bereinigung und Standardisierung entscheidend zur Verbesserung der Datenqualität bei, bevor diese in KI-Systeme eingespeist werden. Schließlich ist ein kontinuierliches Monitoring erforderlich, um sicherzustellen, dass die KI-Modelle stets mit präzisen und aktuellen Informationen trainiert werden.
Zum Partnereintrag:



