Kleine, aber feine KI

Der entscheidende Vorteil von SAP RPT-1 gegenüber den populären LLMs von OpenAI oder Anthropic liegt in der fundamentalen Art und Weise, wie Daten verarbeitet werden. Herkömmliche Sprachmodelle sind brillante Rhetoriker, scheitern aber oft kläglich an der simplen Arithmetik oder der präzisen Interpretation von Zahlenreihen. Wenn ein LLM die Zahl „1000“ sieht, wird diese oft in einzelne Token zerlegt, etwa in „1“, „0“, „0“ und „0“, und als Folge von Zeichen statt als mathematischer Wert behandelt, was bei Berechnungen zu den berüchtigten Halluzinationen führen kann.
RPT-1 und relationale Werte
RPT-1 hingegen erkennt „1000“ als einen einzigen relationalen Wert, was die Präzision bei der Analyse von Geschäftsdaten, wie sie in den SAP-Tabellen MARA oder in Verkaufsdatenbanken zu finden sind, massiv erhöht. Wo ein textbasiertes Modell halluziniert oder den Kontext einer komplexen Tabellenstruktur missversteht, agiert RPT-1 wie ein spezialisierter „GPT für Tabellen“, der die semantische Logik von Zeilen und Spalten nativ versteht, ohne den Umweg über die Sprache gehen zu müssen. In der hitzigen Debatte um künstliche Intelligenz, die meist von den sprachgewandten Alleskönnern aus dem Silicon Valley wie ChatGPT oder Claude dominiert wird, versucht SAP mit einer technischen Nischenlösung Boden gutzumachen, die unter dem kryptischen Kürzel RPT-1 firmiert. Während die Welt staunend auf Large Language Models (LLMs) blickt, die Gedichte schreiben und Code generieren, besinnt sich SAP auf seine eigentliche DNA: die profanen, aber geschäftskritischen Datenbanktabellen.

RPT-1, was für „Relational Pre-trained Transformer“ steht, ist der Versuch, die Transformer-Technologie, die den Erfolg von OpenAI und Anthropic begründete, von der unstrukturierten Welt der Sprache in die hochstrukturierte Welt der relationalen Unternehmensdaten zu übertragen. Es ist SAPs erstes wirkliches „Foundation Model“, das speziell für Tabellen und nicht für Text entwickelt wurde, und markiert damit einen strategisch notwendigen Gegenentwurf zu den sprachbasierten Modellen der US-Konkurrenz. Ein weiterer gravierender Vorteil liegt in der Effizienz und dem Wegfall aufwendiger Trainingsphasen für spezifische Aufgaben. In der traditionellen Welt des maschinellen Lernens (ML) mussten Unternehmen für jedes Problem – sei es die Vorhersage von Kundenabwanderung (Churn), Betrugserkennung oder Bedarfsplanung – ein eigenes, dediziertes Modell trainieren und pflegen, was enorme Ressourcen bei den Data-Science-Teams band.
In-Context Learning
RPT-1 bricht mit diesem Paradigma durch das sogenannte In-Context Learning. Das Modell muss die kundenspezifischen Daten nicht auswendig lernen oder langwierig trainiert werden; stattdessen liest es die Daten während der Inferenzzeit, trifft die Vorhersage und „vergisst“ die Daten sofort wieder, ähnlich einer Prüfung, bei der das Lehrbuch offen auf dem Tisch liegen darf. Dies senkt nicht nur die Hürde für den Einsatz drastisch, sondern reduziert auch den Ressourcenverbrauch im Vergleich zu den Token-hungrigen LLMs der Hyperscaler signifikant, da keine riesigen Textmengen prozessiert werden müssen.
Die Einsatzmöglichkeiten dieses Modells zielen genau in das Herz der ERP-Prozesse. SAP positioniert RPT-1 für Szenarien, in denen Geschwindigkeit und Präzision wichtiger sind als Eloquenz. Eine kleine Version des Modells, der sogenannte Speedster, ist auf millisekundenschnelle Latenzzeiten optimiert und soll beispielsweise betrügerische Transaktionen in Echtzeit blockieren können. Größere Varianten des Modells adressieren komplexe Aufgaben wie die Vorhersage von Lieferkettenengpässen oder Zahlungsrisiken. Aufgaben, an denen herkömmliche ML-Pipelines oft Stunden rechnen, während RPT-1 Ergebnisse fast augenblicklich liefert. Auch für die technische Überwachung der SAP-Landschaft selbst – etwa zur Vorhersage, ob Batch-Jobs oder Schnittstellen am Monatsende scheitern werden – bietet das Modell neue Ansätze für das IT-Betriebsmanagement.
RPT-1 und LLMs
Basierend auf den vorliegenden Quellen (https://community.sap.com/) lässt sich der technische Unterschied zwischen SAP RPT-1 (Relational Pre-trained Transformer) und den LLM-Ansätzen von OpenAI (wie GPT) fundamental an der Art der Datenverarbeitung und der Architektur festmachen, siehe Kasten. Während OpenAI-Modelle Sprachmodelle für unstrukturierte Textdaten sind, ist RPT-1 ein spezialisiertes Foundation Model für strukturierte, tabellarische Geschäftsdaten.
Doch bei aller technischen Finesse darf eine kritische Einordnung nicht fehlen. In der SAP-Community wird RPT-1 teils skeptisch als Teil einer „KI-Chaostheorie“ betrachtet. Kritiker merken an, dass es sich bei RPT-1 faktisch um ein „schmalspuriges“ LLM handelt, das möglicherweise lediglich alten Wein in neuen Schläuchen verkauft. Es besteht der Verdacht, dass unter der Haube weiterhin Mechanismen wie die „Predictive Analysis Library“ (PAL) der Hana-Datenbank
arbeiten, ergänzt um moderne Marketingbegriffe, um den Anschluss an den KI-Hype nicht zu verlieren.
Abap-Tabellen „only“
Zudem ist RPT-1, so innovativ der Ansatz für Tabellen auch sein mag, in seiner Anwendungsbreite limitiert: Es arbeitet ausschließlich auf Tabellen, nicht auf Text oder Bildern, und ist damit kein Ersatz, sondern höchstens eine Ergänzung zu den mächtigen Modellen von OpenAI. Während SAP versucht, mit RPT-1 die Hoheit über die „Business-Semantik“ zurückzugewinnen, bleibt abzuwarten, ob dieser spezialisierte Ansatz ausreicht, um gegen die schiere Übermacht und Innovationsgeschwindigkeit der Generativen-KI-Giganten zu bestehen, die zunehmend lernen, auch mit strukturierten Daten besser umzugehen. RPT-1 ist somit SAPs Wette darauf, dass im ERP-Umfeld am Ende die nackten Zahlen mehr zählen als schöne Worte. (pmf)
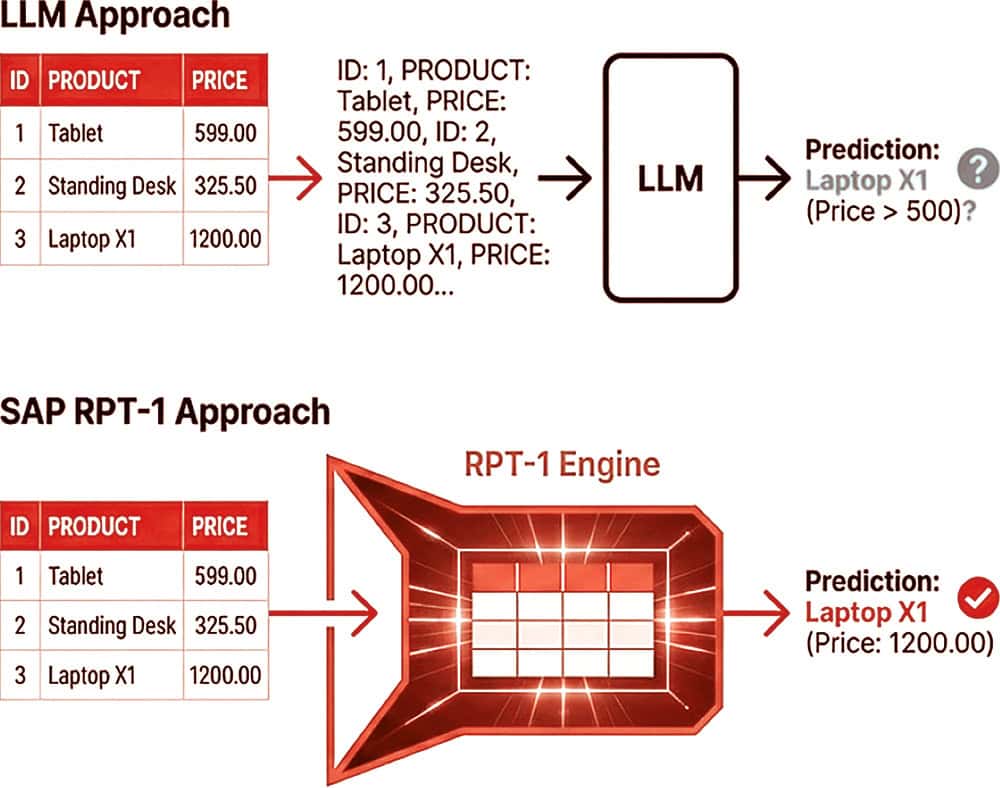
SAP RPT-1 versus ChatGPT
Datenmodalität: Tabelle vs. Text. Bei OpenAI (LLM) sind die Modelle darauf trainiert, natürliche Sprache zu verstehen und zu generieren. Sie arbeiten mit unstrukturiertem Text. SAP RPT-1 wurde speziell für tabellarische Daten entwickelt. Es fungiert als „GPT für Tabellen“. Es versteht die Struktur von Zeilen und Spalten (wie in SAP-Tabellen MARA oder Sales-Daten) nativ, anstatt sie als Text zu interpretieren.
Tokenisierung und Zahlenverständnis (das „1000“-Problem): Ein technischer Unterschied liegt in der Behandlung von numerischen Werten. Wenn OpenAI (LLM) die Zahl „1000“ sieht, wird diese oft tokenisiert und in separate Zeichen zerlegt. Das Modell versucht dann, Mathematik auf Basis dieser Textzeichen durchzuführen, was häufig zu Halluzinationen oder Rechenfehlern führt. RPT-1 erkennt „1000“ als einen einzelnen relationalen Wert. Es versteht die mathematische Bedeutung und den Kontext der Zahl innerhalb der Tabellenstruktur, was präzisere Vorhersagen bei Geschäftsdaten ermöglicht.
Lernverfahren: In-Context Learning vs. Fine-Tuning. Um spezifische Unternehmensaufgaben zu lösen, müssen LLMs von OpenAI oft aufwendig mit neuen Daten feinjustiert (Fine-Tuning) werden oder benötigen komplexe RAG-Architekturen (Retrieval-Augmented Generation), um Kontext zu erhalten. SAP RPT-1 nutzt In-Context Learning. Das Modell muss nicht für jede Aufgabe
(z. B. Churn-Prediction oder Betrugserkennung) neu trainiert werden. Es liest die Daten zur Laufzeit (Inference Time), trifft die Vorhersage und „vergisst“ die Daten danach wieder.
Ressourcen und Effizienz: OpenAI (LLM) ist ressourcenhungrig, verbraucht viele Token und benötigt massive Rechenleistung (GPUs) für die Verarbeitung von Kontext. SAP RPT-1 ist auf die tabellarische Struktur optimiert, somit verbraucht es signifikant weniger Ressourcen (Token) und führt weniger Rechenoperationen (FLOPs) aus. Es ist effizienter für Aufgaben wie das Füllen fehlender Werte in einer Datenbank oder die Vorhersage von Zeitreihen.

