Lien de données manquant


Intégration des données : accès en temps réel pour des décisions en temps réel
Il faut prendre des décisions rapides, pour lesquelles un accès en temps réel aux données est nécessaire. Trois obstacles se dressent sur cette voie, que nous allons examiner de plus près dans cet article. L'exemple de Pitney Bowes, un fournisseur mondial de solutions d'expédition et de traitement du courrier, de logistique de commerce électronique et de services financiers, montre ensuite comment les entreprises peuvent les surmonter.
99 % des entreprises sont confrontées à des problèmes d'intégration de données. Pour 65% d'entre elles, l'accès aux données ERP est déjà difficile. Ce sont les résultats d'une récente enquête mondiale menée par Dimensional Research et Fivetran auprès de professionnels de l'ERP. Les conséquences du manque d'accès aux données sont massives : 82 pour cent des experts ERP interrogés déclarent que leur entreprise travaille avec des données obsolètes. Pour 85 % d'entre eux, c'est la cause de mauvaises décisions. Environ 70 pour cent citent comme problème les retards dans l'analyse des données et donc aussi dans les prises de décision importantes. Moins d'un quart des personnes interrogées ont actuellement un accès en temps réel aux données ERP. Pourquoi cette proportion est-elle si faible ici ? Trois obstacles compliquent l'intégration des données ERP SAP pour les entreprises.

La charge importante que représentent les données ERP SAP isolées pour les entreprises.
Accès limité
Plusieurs facteurs rendent l'accès en temps réel difficile. Parmi les plus importants, on peut citer : l'immense quantité de données stockées dans les systèmes SAP ; la vitesse à laquelle de nouvelles données sont constamment générées ; et la diversité des différents formats et sources de données.
Mais l'accès n'est pas le seul problème. Il s'y ajoute le fait que les données ne sont pas disponibles en permanence, mais qu'elles sont au contraire très volatiles. De plus, l'accès seul ne suffit pas. Ce n'est qu'en reliant les données SAP à des données provenant d'autres systèmes d'entreprise et de sources externes - idéalement en temps réel - que les entreprises peuvent en tirer des enseignements. Là encore, beaucoup échouent. Car le rythme de génération de nouvelles données ne cesse d'augmenter. Et l'utilisation toujours croissante des smartphones et des médias sociaux ainsi que des processus commerciaux interactifs engendre une complexité souvent paralysante. C'est particulièrement vrai lorsqu'il s'agit d'intégrer les données ERP avec d'autres fonctions opérationnelles comme le CRM, les ventes ou des sources non structurées. Pourtant, c'est la seule façon pour les entreprises d'obtenir une vue unifiée de leurs données - et un énorme potentiel pour les exploiter.
Par exemple, pour obtenir des informations utiles à partir de données OLTP (Online Transactional Processing) au moyen d'OLAP (Online Analytical Processing), les données doivent être extraites, transformées et chargées dans un entrepôt de données pour être analysées. Jusqu'à présent, il n'était pas courant de synchroniser en permanence les systèmes OLTP et OLAP. Au lieu de cela, les données étaient chargées quotidiennement ou mensuellement dans les systèmes d'analyse à l'aide de pipelines de données développés en interne et de processus manuels. Les utilisateurs ont ainsi accès aux données, mais celles-ci sont obsolètes.
Pas d'intégration transparente
Ce sujet place les entreprises devant la tâche de trouver l'équilibre idéal entre, d'une part, l'accès aux données SAP à la vitesse et à l'échelle nécessaires et, d'autre part, les coûts d'installation, de licence ou de développement des outils correspondants. Jusqu'à présent, cela ne posait guère de problème, car les données ERP n'étaient exportées que de manière ciblée, à des fins bien précises. Mais entre-temps, il est devenu de plus en plus critique pour les entreprises de rendre utilisables rapidement et de manière évolutive d'énormes quantités de données d'entreprise.
Pour maintenir les coûts à un niveau aussi bas que possible, de nombreuses entreprises construisent leurs propres pipelines de données. Leurs spécialistes des données sont toutefois confrontés à la tâche presque insurmontable de suivre l'explosion des volumes de données. De nouvelles lignes de produits et de nouveaux ensembles de données sont constamment ajoutés, ce qui oblige les entreprises à adapter continuellement leurs pipelines de données, voire à en construire de nouveaux. Cela complique non seulement l'intégration transparente des données, mais prend aussi beaucoup de temps précieux aux data scientists et aux data engineers.
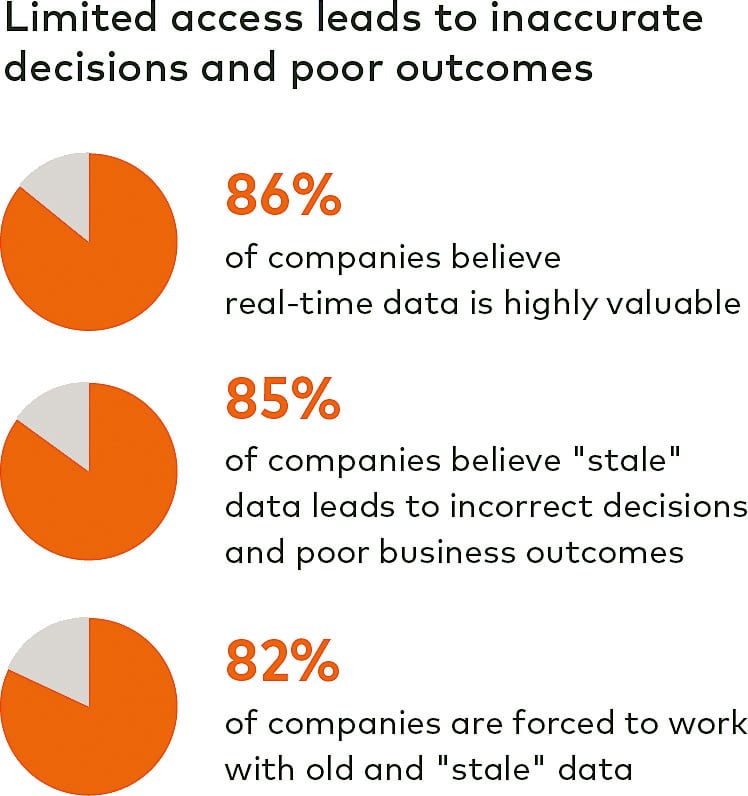
Un accès limité conduit à des décisions imprécises et à de mauvais résultats.
Pas d'utilisation optimale
Plusieurs raisons expliquent le fait que de nombreuses entreprises ne parviennent pas à tirer pleinement profit de leurs données ERP SAP : La complexité, les données réparties dans différents silos et sources, par exemple dans le cloud et sur site ; le manque de spécialistes qualifiés freine le développement de pipelines de données DIY ; et les préoccupations en matière de sécurité ou le manque de concepts robustes de sécurité et de protection des données empêchent de nombreuses entreprises d'exploiter leurs données ERP SAP.
Comment les entreprises peuvent-elles surmonter ces obstacles ? Seuls des pipelines de données évolutifs et automatisés permettent aux entreprises d'utiliser leurs données SAP de manière à en tirer le meilleur parti. C'est la seule façon de maîtriser les volumes croissants de données, d'intégrer les données ERP SAP avec des systèmes de données non structurés et d'obtenir des informations en temps réel. La manière la plus économique d'atteindre cet objectif est de répliquer de grandes quantités de données à l'aide de la technologie Change-Data-Capture (CDC) basée sur les logs. La réplication des données consiste à copier en continu les données qui se trouvent sur un serveur physique ou virtuel ou dans un nuage sur un deuxième serveur ou une deuxième instance de nuage.
Lorsqu'il s'agit de données ERP, une telle solution de réplication de données doit être capable de traiter les immenses quantités de données en question. Pour un accès en temps (presque) réel, elle doit également être en mesure d'enregistrer les modifications sur le serveur primaire - le système SAP - et de les transmettre en temps réel à un système cible - une plateforme en nuage ou un entrepôt de données.
Il existe plusieurs méthodes CDC pour répliquer les modifications entre les bases de données. Pour les grands volumes de données, la technologie CDC basée sur la logique est recommandée. Elle est considérée comme une méthode de réplication supérieure, car elle permet de traiter rapidement de grandes quantités de données avec un impact minimal sur les sources de transaction.
Les structures de données d'un système SAP doivent prendre en compte et intégrer de nombreux satellites.
Meilleure pratique
Pitney Bowes propose des solutions d'expédition et de traitement du courrier, une logistique de commerce électronique et des services financiers utilisés par quelque 750 000 clients dans le monde entier. Son équipe de gestion de l'information d'entreprise (EIM) extrayait chaque nuit des données à la fois de SAP et d'Oracle pour le reporting des ventes. Le volume d'intégration des données de SAP vers Snowflake avait considérablement augmenté, le processus ETL par lots nécessitant jusqu'à 31 heures. De plus, le nombre croissant d'entreprises qui demandaient des données SAP pour des tableaux de bord et des rapports ne pouvait plus être géré avec les anciens processus ETL.
Comme le système existant n'était pas suffisamment évolutif pour répondre à ces exigences croissantes, Pitney Bowes a opté pour un outil CDC de Fivetran. Outre la grande flexibilité, la vitesse et l'évolutivité, l'intégration transparente avec la base de données Snowflake a également joué un rôle dans le choix. De plus, Pitney Bowes avait du mal à trouver une solution compatible avec SAP. Fivetran a marqué des points avec un ensemble de fonctionnalités permettant à Pitney Bowes de répliquer facilement à partir de SAP.
Aujourd'hui, Pitney Bowes synchronise, valide et réplique quatre fois par jour les données d'Oracle et de SAP dans l'entrepôt de données basé sur le cloud. Les utilisateurs ont ainsi accès à des données SAP et Oracle en leasing actualisées en tant que "source unique de vérité" dans une base de données d'entreprise sans aucun impact sur les applications sources. La majeure partie de la gestion de la réplication se fait via l'interface. Cela signifie que la surveillance manuelle requise pour le traitement par lots n'est plus nécessaire.
Pitney Bowes a constaté des temps de traitement nettement plus rapides, tant pour ses systèmes Oracle que SAP. Les tâches ETL qui prenaient auparavant des jours sont désormais effectuées en moins d'une heure. L'équipe EIM peut ainsi répondre aux demandes croissantes de données Oracle en leasing et de données SAP. De plus, l'"empreinte technique" du processus de collecte de données a été minimisée, ce qui signifie que les licences logicielles redondantes ont pu être résiliées et que le matériel et le stockage des données ont été réduits.



