Une IA petite mais efficace

L'avantage décisif de SAP RPT-1 par rapport aux LLM populaires d'OpenAI ou d'Anthropic réside dans la manière fondamentale dont les données sont traitées. Les modèles linguistiques traditionnels sont de brillants rhétoriciens, mais échouent souvent lamentablement face à la simple arithmétique ou à l'interprétation précise de séries de nombres. Lorsqu'un LLM voit le nombre „1000“, il le décompose souvent en jetons individuels, comme „1“, „0“, „0“ et „0“, et le traite comme une suite de caractères plutôt que comme une valeur mathématique, ce qui peut entraîner les fameuses hallucinations lors des calculs.
RPT-1 et valeurs relationnelles
RPT-1, en revanche, reconnaît „1000“ comme une valeur relationnelle unique, ce qui augmente considérablement la précision de l'analyse des données commerciales, comme celles que l'on trouve dans les tables MARA de SAP ou dans les bases de données de vente. Là où un modèle basé sur du texte hallucine ou se méprend sur le contexte d'une structure de table complexe, RPT-1 agit comme un „GPT pour tables“ spécialisé, qui comprend nativement la logique sémantique des lignes et des colonnes sans devoir passer par le langage. Dans le débat houleux sur l'intelligence artificielle, dominé la plupart du temps par les touche-à-tout de la Silicon Valley qui savent parler, comme ChatGPT ou Claude, SAP tente de gagner du terrain avec une solution technique de niche, désignée par l'abréviation énigmatique RPT-1. Alors que le monde regarde avec étonnement les Large Language Models (LLM) qui écrivent des poèmes et génèrent du code, SAP se recentre sur son véritable ADN : les tables de base de données profanes mais critiques pour l'entreprise.
RPT-1, qui signifie „Relational Pre-trained Transformer“, est une tentative de transférer la technologie des transformateurs, qui a fait le succès d'OpenAI et d'Anthropic, du monde non structuré du langage au monde hautement structuré des données relationnelles d'entreprise. Il s'agit du premier véritable „Foundation Model“ de SAP, développé spécifiquement pour les tableaux et non pour le texte, et marque ainsi une opposition stratégiquement nécessaire aux modèles basés sur le langage de la concurrence américaine. Un autre avantage sérieux réside dans l'efficacité et la suppression des phases d'entraînement coûteuses pour des tâches spécifiques. Dans le monde traditionnel de l'apprentissage automatique (ML), les entreprises devaient former et entretenir un modèle dédié pour chaque problème - qu'il s'agisse de prédire l'attrition des clients (churn), de détecter les fraudes ou de planifier la demande -, ce qui mobilisait d'énormes ressources au sein des équipes de science des données.
Apprentissage dans le contexte
RPT-1 rompt avec ce paradigme grâce à ce que l'on appelle l'apprentissage dans le contexte. Le modèle n'a pas besoin d'apprendre par cœur les données spécifiques au client ou d'être longuement entraîné ; au lieu de cela, il lit les données pendant le temps d'inférence, fait la prédiction et „oublie“ immédiatement les données, un peu comme un examen où le manuel peut être laissé ouvert sur la table. Cela réduit non seulement de manière drastique l'obstacle à l'utilisation, mais aussi de manière significative la consommation de ressources par rapport aux LLM des hypercalculateurs, gourmands en jetons, car il n'est pas nécessaire de traiter d'énormes quantités de texte.
Les possibilités d'utilisation de ce modèle visent précisément le cœur des processus ERP. SAP positionne RPT-1 pour les scénarios dans lesquels la vitesse et la précision sont plus importantes que l'éloquence. Une petite version du modèle, appelée Speedster, est optimisée pour des temps de latence de l'ordre de la milliseconde et doit par exemple pouvoir bloquer des transactions frauduleuses en temps réel. Des variantes plus grandes du modèle s'adressent à des tâches complexes telles que la prédiction de goulots d'étranglement dans la chaîne d'approvisionnement ou de risques de paiement. Des tâches sur lesquelles les pipelines ML traditionnels passent souvent des heures à calculer, alors que RPT-1 fournit des résultats presque instantanément. Le modèle offre également de nouvelles approches pour la gestion des opérations informatiques en ce qui concerne la surveillance technique de l'environnement SAP lui-même - par exemple pour prédire si des tâches par lots ou des interfaces vont échouer à la fin du mois.
RPT-1 et LLMs
Sur la base des sources disponibles (https://community.sap.com/), la différence technique entre SAP RPT-1 (Relational Pre-trained Transformer) et les approches LLM d'OpenAI (comme GPT) peut être fondamentalement déterminée par le type de traitement des données et l'architecture, voir encadré. Alors que les modèles OpenAI sont des modèles de langage pour les données textuelles non structurées, RPT-1 est un modèle de fondation spécialisé pour les données commerciales structurées et tabulaires.
Mais malgré toute la finesse technique, une classification critique ne doit pas manquer. Dans la communauté SAP, RPT-1 est parfois considéré avec scepticisme comme faisant partie d'une „théorie de la chaîne d'IA“. Les critiques font remarquer que RPT-1 est en fait un LLM „étroit“ qui ne fait peut-être que vendre du vieux vin dans de nouvelles outres. On soupçonne que sous le capot, des mécanismes tels que la „Predictive Analysis Library“ (PAL) de la base de données Hana
Les entreprises doivent travailler avec des concepts de marketing modernes, afin de ne pas perdre le contact avec l'engouement pour l'IA.
Tables Abap „only“
De plus, aussi innovante que soit l'approche des tableaux, RPT-1 est limitée dans son champ d'application : Il travaille exclusivement sur des tableaux, et non sur du texte ou des images, et ne constitue donc pas un remplacement, mais tout au plus un complément aux puissants modèles d'OpenAI. Alors que SAP tente de reprendre la main sur la „sémantique métier“ avec RPT-1, il reste à voir si cette approche spécialisée suffira à résister à la toute-puissance et à la vitesse d'innovation des géants de l'IA générative, qui apprennent de plus en plus à mieux traiter les données structurées. RPT-1 est donc le pari de SAP que dans l'environnement ERP, les chiffres bruts comptent finalement plus que les belles paroles. (pmf)
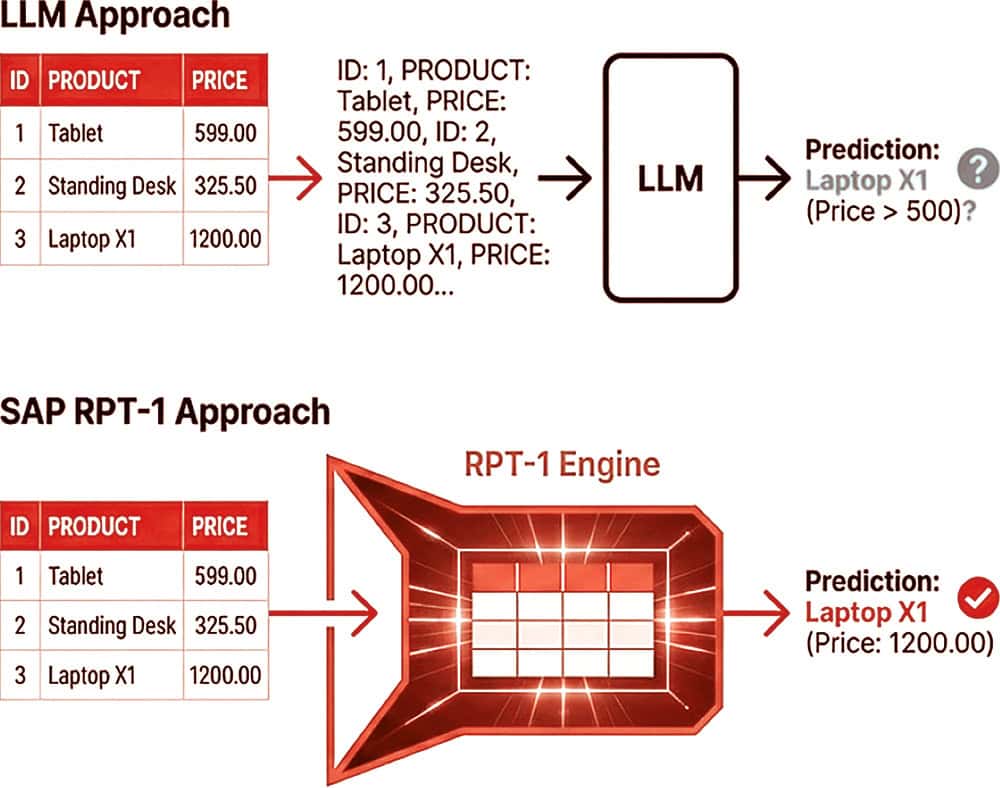
SAP RPT-1 versus ChatGPT
Modalité des données : tableau vs. texte. Avec OpenAI (LLM), les modèles sont entraînés à comprendre et à générer du langage naturel. Ils travaillent avec du texte non structuré. SAP RPT-1 a été spécialement conçu pour les données tabulaires. Il fait office de „GPT pour les tableaux“. Il comprend nativement la structure des lignes et des colonnes (comme dans les tables SAP MARA ou les données de vente) au lieu de les interpréter comme du texte.
Tokenisation et compréhension des nombres (le problème du „1000“) : Une différence technique réside dans le traitement des valeurs numériques. Lorsque OpenAI (LLM) voit le nombre „1000“, celui-ci est souvent tokenisé et décomposé en caractères séparés. Le modèle tente alors d'effectuer des mathématiques sur la base de ces caractères de texte, ce qui conduit souvent à des hallucinations ou à des erreurs de calcul. RPT-1 reconnaît „1000“ comme une valeur relationnelle unique. Il comprend la signification mathématique et le contexte du nombre dans la structure de la table, ce qui permet des prédictions plus précises pour les données commerciales.
Procédures d'apprentissage : Apprentissage dans le contexte vs. réglage fin. Pour résoudre des tâches d'entreprise spécifiques, les LLM d'OpenAI doivent souvent être ajustés finement et à grands frais avec de nouvelles données (Fine-Tuning) ou nécessitent des architectures RAG (Retrieval-Augmented Generation) complexes pour conserver le contexte. SAP RPT-1 utilise l'apprentissage in-context. Le modèle ne doit pas être utilisé pour chaque tâche
(p. ex. prédiction de churn ou détection de fraude). Il lit les données au moment de l'exécution (Inference Time), fait la prédiction et „oublie“ ensuite les données.
Ressources et efficacité : OpenAI (LLM) est gourmand en ressources, consomme beaucoup de jetons et nécessite une puissance de calcul massive (GPU) pour le traitement du contexte. SAP RPT-1 est optimisé pour la structure tabulaire, il consomme donc significativement moins de ressources (jetons) et exécute moins d'opérations de calcul (FLOPs). Il est plus efficace pour des tâches telles que le remplissage de valeurs manquantes dans une base de données ou la prédiction de séries temporelles.


