L'anonymat est plus sûr


Les données sont une valeur essentielle pour les entreprises. Les technologies du big data, apparues ces dernières années, permettent de stocker des données en masse, parmi lesquelles figurent bien sûr en grande partie des données personnelles.
Toutefois, le stockage et le traitement de ces données sont soumis à des dispositions légales. Le Code civil allemand (BGB), avec sa réserve de propriété qui s'applique également aux données, ainsi que les réglementations spéciales dans les domaines correspondants, comme par exemple le Code social allemand (SGB X) avec les obligations relatives aux données des patients, en constituent les bases.
Avec son entrée en vigueur fin mai 2018, le règlement européen sur la protection des données (EU-DSGVO) et ses adaptations nationales remplaceront également l'ancienne loi fédérale sur la protection des données.
En résumé, cela signifie que, par défaut, il est interdit de stocker des données à caractère personnel. Toutes ces règles définissent toutefois des exceptions.
Une telle exception, telle qu'elle est généralement mise en œuvre aujourd'hui, est un consentement lié à l'exécution d'une relation commerciale - par exemple pour l'exécution d'une commande, la fourniture d'un service, l'envoi d'une newsletter.
Les autorisations donnent toutefois rapidement l'impression que ces données peuvent, elles aussi, être traitées presque à volonté, comme les autres données de l'entreprise. Les entreprises doivent cependant être très attentives à l'endroit où les données sont stockées et traitées.
Les données personnelles n'ont pas leur place sur le système de test
L'utilisation de données à caractère personnel sur des systèmes de test et d'assurance qualité ou pour des systèmes de développement est critique, tant dans l'environnement SAP que dans un environnement non SAP. Même un consentement ne permet pas d'y traiter des données à caractère personnel, car le consentement est souvent recueilli dans un but précis, comme décrit ci-dessus.
Cela n'inclut pas automatiquement le développement et les tests. Même dans le cas de l'analyse des données volumineuses, on cite trop volontiers des concepts qui améliorent la vision globale du client.
C'est la seule façon de vendre au client des produits et des services encore meilleurs et adaptés à ses besoins. Pour cela, il faudrait bien sûr collecter, stocker et analyser un grand nombre de données détaillées sur les individus.
Les scénarios Big Data se réfèrent donc souvent à des données à caractère personnel, ce qui n'est toutefois pas obligatoire. Il est prouvé que les données non personnelles permettent également de développer de nouveaux modèles commerciaux intéressants.
L'une des principales tendances informatiques pour 2018 sera la commercialisation des données par les entreprises utilisatrices. Le cabinet d'études IDC, entre autres, a confirmé que d'ici 2020, environ 90 % des grandes entreprises généreront des revenus directs en vendant des données brutes ou à partir des connaissances ou des recommandations qui en découlent.
En 2017, ce chiffre était encore de 50 %. Les données sont donc une ressource qui peut être exploitée, stockée et valorisée. La technique de collecte, de stockage et de valorisation des données s'est développée ces dernières années, que ce soit grâce à des systèmes de stockage peu coûteux ou à de nouveaux concepts de bases de données.
L'une des tâches importantes des directeurs informatiques et des responsables de la transformation numérique sera donc de mettre la commercialisation de leurs propres données sur les rails, et sur la bonne voie.
La capitalisation des données est tout à fait à la mode. Toutefois, en raison des dispositions légales mentionnées, il ne peut s'agir que rarement de données à caractère personnel.
Anonymiser ou supprimer ?
Il n'y a pas de problème pour la capitalisation d'informations avec des données anonymes. La société Libelle AG de Stuttgart, connue jusqu'à présent pour ses solutions autour de la haute disponibilité des bases de données SAP et non-SAP et des copies de systèmes SAP et non-SAP, a développé son savoir-faire dans ces deux domaines et a mis au point Libelle DataMasking (LDM), une solution pour l'anonymisation et la pseudonymisation nécessaires.
La solution a été conçue pour produire des données anonymisées et logiquement cohérentes sur les systèmes de développement, de test et d'assurance qualité sur toutes les plates-formes. Les méthodes d'anonymisation utilisées fournissent des valeurs réalistes et logiquement correctes qui permettent de décrire presque tous les cas d'entreprise et de les tester de manière pertinente de bout en bout.
Parmi les approches de traitement des données critiques, en particulier des données à caractère personnel, avant leur transfert ou leur traitement ultérieur, on trouve la pseudonymisation et l'anonymisation. Toutefois, une bonne anonymisation peut être plus difficile à réaliser qu'il n'y paraît à première vue.
Une possibilité simple consiste à supprimer ou à écraser les données critiques réelles sur les systèmes non productifs. Toutefois, les enregistrements individuels perdent alors leurs liens logiques et leurs dépendances les uns par rapport aux autres - et donc leur valeur utile.
Pseudonymisation
La pseudonymisation consiste à remplacer des données réelles par des données erronées, généralement de simples valeurs numériques. Toutefois, il ne suffit souvent pas de remplacer, par exemple, le nom, le prénom et la date de naissance ou des valeurs similaires dans la base de données clients par des valeurs erronées.
Souvent, une simple comparaison de telles bases de données avec des annuaires téléphoniques accessibles au public suffit à rétablir également la référence aux personnes. C'est pourquoi il convient d'utiliser des procédures spéciales de haute qualité pour l'anonymisation.
Libelle DataMasking est une solution pour le traitement automatisé de données sensibles. Elle permet de traiter des ensembles de données aussi complexes que l'on veut avec des méthodes d'anonymisation complètes.
Des fonctions préconfigurées peuvent être appliquées rapidement et facilement aux champs de données qui ont été identifiés comme critiques et sensibles. Les responsables professionnels et/ou techniques peuvent ainsi recourir à des règles standardisées et, en outre, établir des règles aussi complexes qu'ils le souhaitent, permettant par exemple de calculer des types de données hautement structurés et parlants.
Des données propres pour le développement et les tests
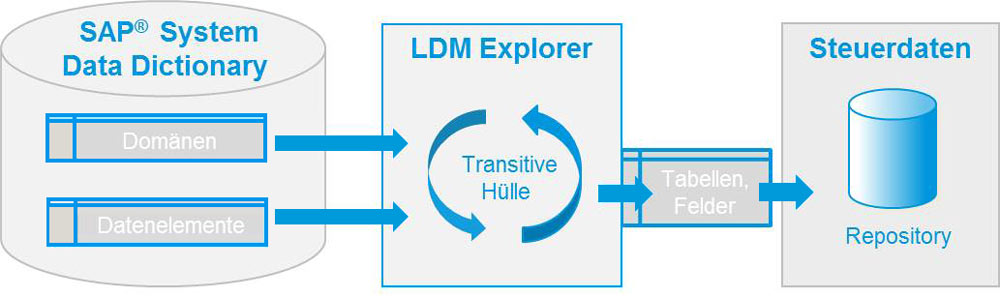
Il n'est pas toujours évident pour les responsables et les programmeurs d'applications de savoir quelles données font réellement partie des données sensibles. L'un des composants centraux de la solution d'anonymisation de Libelle est le LDM Explorer, qui permet d'analyser les bases de données et les systèmes de fichiers ainsi que leurs modèles de données respectifs, une seule fois ou de manière répétée après des modifications structurelles, afin de déterminer les contenus à anonymiser.
Les personnes responsables examinent, vérifient et, le cas échéant, complètent les résultats de LDM Explorer pour les associer ensuite, via LDM Assoziator, à des procédures d'anonymisation typiques.
Cela constitue la base d'une anonymisation automatique, logique et cohérente d'ensembles de données connexes au-delà des limites du système. Pour les situations standard, LDM propose actuellement 75 profils d'anonymisation standardisés.
Une fois les données identifiées et associées aux procédures d'anonymisation correspondantes, les étapes d'anonymisation opérationnelles du LDM entrent en jeu. Celles-ci traitent alors déjà out of the box, outre les cas spéciaux spécifiques à l'entreprise, les champs de noms, les informations d'adresse, les données bancaires et les données telles que la date de naissance, la date de commande. Les index sont également reconstruits, dans la mesure où ils sont concernés.
Autres scénarios
Les développeurs et les utilisateurs disposent ainsi d'une base de données "propre" avec laquelle ils n'ont pas à se soucier de la protection des données. De nombreux autres scénarios d'utilisation de Libelle DataMasking sont envisageables, dont les exemples cités au début pour la transmission de données anonymisées dans le cadre d'une chaîne d'approvisionnement, dans le contexte d'un pool de données ouvert ou lors d'une commercialisation.
