El anonimato es más seguro


Los datos son un activo central de las empresas. Las tecnologías de big data surgidas en los últimos años permiten el almacenamiento masivo de datos, incluidos, por supuesto, una gran cantidad de datos personales.
Sin embargo, el almacenamiento y el tratamiento precisamente de estos datos están sujetos a requisitos legales. La base para ello es, entre otros, el Código Civil alemán (BGB) con su conservación de la titularidad, que también se aplica a los datos, así como normativas especiales en los entornos correspondientes, como el SGB X con los requisitos para los datos de pacientes.
Cuando entre en vigor a finales de mayo de 2018, el Reglamento General de Protección de Datos europeo (RGPD de la UE), con sus respectivas adaptaciones nacionales, sustituirá también a la anterior Ley Federal de Protección de Datos.
Al final, esto significa: por defecto, no está permitido almacenar datos personales. Sin embargo, todas estas normativas también definen excepciones en las que vuelve a estar permitido.
Dicha excepción, tal y como suele aplicarse hoy en día, es un consentimiento vinculado a una finalidad para el cumplimiento de una relación comercial, por ejemplo, para la ejecución de un pedido, la prestación de un servicio o el envío de un boletín informativo.
Sin embargo, los permisos dan rápidamente la impresión de que estos datos, al igual que otros datos de la empresa, pueden procesarse casi a voluntad. Sin embargo, las empresas deben prestar mucha atención a dónde se almacenan y procesan los datos: los datos personales están sujetos a una protección especial.
Los datos personales no pertenecen al sistema de pruebas
El uso de datos personales en sistemas de prueba y control de calidad o para sistemas de desarrollo es crítico, tanto en el entorno SAP como en el no SAP. Ni siquiera el consentimiento permite el tratamiento de datos personales allí, porque el consentimiento suele recabarse para un fin específico, como se ha descrito anteriormente.
Esto no incluye automáticamente el desarrollo y las pruebas. Incluso con el análisis de big data, los conceptos que mejoran la visión global del cliente se mencionan con demasiada facilidad.
Sólo así se podrá vender a los clientes productos y servicios aún mejores y más adecuados para ellos. Por supuesto, esto exigiría recopilar, almacenar y analizar muchos datos detallados sobre el individuo.
Así, los escenarios de Big Data se refieren a menudo a datos personales, que en esencia no son absolutamente necesarios. Incluso con datos no personales es posible desarrollar nuevos e interesantes modelos de negocio.
Una de las tendencias informáticas más importantes de 2018 será la comercialización de datos por parte de las empresas usuarias. La empresa de estudios de mercado IDC, entre otras, confirmó que en 2020, alrededor del 90 % de las grandes empresas generarán ingresos directos por la venta de datos en bruto o de percepciones o recomendaciones derivadas de ellos.
En 2017, seguía siendo del 50%. Los datos son, por tanto, un recurso que puede aprovecharse, almacenarse y refinarse. La tecnología para recopilar, almacenar y refinar datos se ha seguido desarrollando en los últimos años, ya sea mediante sistemas de almacenamiento rentables o nuevos conceptos de bases de datos.
Por lo tanto, una de las tareas importantes de los directores de TI y los responsables de la transformación digital será encaminar correctamente la comercialización de sus propios datos.
La capitalización de datos está plenamente en boga. Sin embargo, debido a las disposiciones legales antes mencionadas, sólo en contadas ocasiones puede tratarse de datos personales.
¿Anonimizar o eliminar?
No hay problemas con la capitalización de la información con datos anonimizados. Libelle AG de Stuttgart, conocida anteriormente por sus soluciones en torno a la alta disponibilidad de bases de datos SAP y no SAP y copias de sistemas SAP y no SAP, ha seguido desarrollando los conocimientos de estos dos temas y con Libelle DataMasking (LDM) ha desarrollado una solución para la anonimización y seudonimización necesarias.
La solución se diseñó para producir datos anónimos y lógicamente coherentes sobre sistemas de desarrollo, pruebas y control de calidad en todas las plataformas. Los métodos de anonimización utilizados proporcionan valores realistas y lógicamente correctos con los que pueden describirse casi todos los casos empresariales y probarse de forma significativa de extremo a extremo.
Entre los métodos para tratar los datos críticos, especialmente los personales, antes de su divulgación o tratamiento posterior figuran la seudonimización y la anonimización. Sin embargo, una buena anonimización puede ser más difícil de lo que parece a primera vista.
Una posibilidad sencilla es borrar o sobrescribir los datos reales críticos en los sistemas no productivos. Sin embargo, los conjuntos de datos individuales pierden sus conexiones y dependencias lógicas entre sí, y por tanto su utilidad.
Pseudonimización
La seudonimización consiste en sustituir los datos reales por datos falsos, normalmente valores numéricos simples. Sin embargo, en muchos casos no basta con sustituir, por ejemplo, los apellidos, el nombre y la fecha de nacimiento o similares de la base de datos de clientes por valores falsos.
A menudo, basta una simple comparación de estas bases de datos con guías telefónicas de acceso público para recuperar también la referencia personal. Por lo tanto, deben utilizarse procedimientos especiales de alta calidad para la anonimización.
Libelle DataMasking es una solución para el tratamiento automatizado de datos sensibles. Permite manejar conjuntos de datos arbitrariamente complejos con métodos de anonimización exhaustivos.
Las funciones preconfiguradas pueden aplicarse rápida y fácilmente a los campos de datos que se hayan identificado como críticos y sensibles. De este modo, los gestores profesionales y/o técnicos pueden recurrir a reglas estandarizadas y, además, establecer reglas arbitrariamente complejas con las que calcular, por ejemplo, tipos de datos altamente estructurados y parlantes.
Datos limpios para desarrollo y pruebas
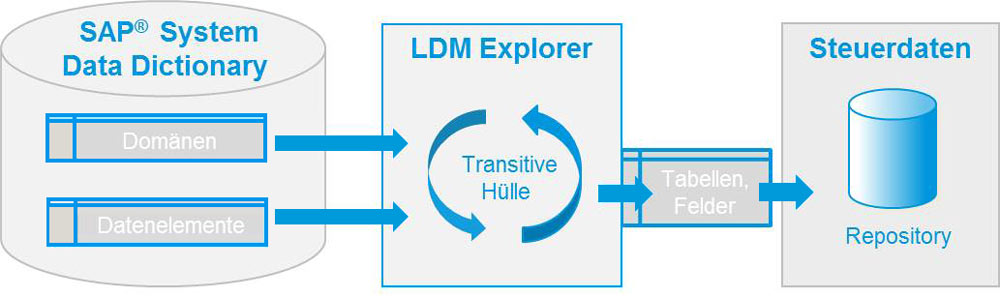
No siempre es obvio para los administradores y programadores de aplicaciones qué datos pertenecen realmente a los datos sensibles. Un componente central de la solución de anonimización de Libelle es el LDM Explorer para el análisis único o, tras cambios estructurales, también recurrente de bases de datos y sistemas de archivos y sus respectivos modelos de datos en busca de contenidos que deban anonimizarse.
Las personas responsables comprueban, verifican y, en caso necesario, completan los resultados del LDM Explorer para luego vincularlos a los procedimientos típicos de anonimización a través del LDM Associator.
Esto constituye la base para una anonimización automática, lógicamente continua y coherente de conjuntos de datos relacionados a través de los límites del sistema. LDM ofrece actualmente 75 perfiles de anonimización normalizados para situaciones estándar.
Una vez identificados los datos y vinculados a los correspondientes procedimientos de anonimización, entran en vigor los pasos operativos de anonimización del LDM. Además de los casos especiales específicos de la empresa, estos pasos ya se ocupan de los campos de nombre, la información de dirección, los datos bancarios y datos como la fecha de nacimiento y la fecha de pedido. Los índices también se reconstruyen en la medida en que se vean afectados.
Otros escenarios
Los desarrolladores y usuarios disponen así de una base de datos "limpia" con la que no tienen que preocuparse por la protección de datos. Existen muchos otros escenarios de aplicación para Libelle DataMasking, incluidos los ejemplos mencionados al principio para compartir datos anonimizados dentro de una cadena de suministro, en el contexto de un pool de datos abiertos o en marketing comercial.


